
On June 25, Google brought its Search Central Live to Paris for the very first time, the first-ever French edition, opened in French by Faten Dubary (Director, News Partnerships France-MEA) in front of 200+ people: press editors, media groups, SEOs and developers. Before I get to what actually stuck with me, let’s clear the elephant out of the room because it’s the question everyone walked in with.

AI Overviews and AI Mode in France: still no date at Search Central Live Paris 2026
Let’s be blunt: Google announced nothing about AI Overviews and AI Mode coming to France. Nothing, despite the rumors that keep piling up. The new features shown on stage were even explicitly stamped “not available in France.” They show you the car; they won’t let you drive it.
The French crowd pushed, of course. Same answer as always: the classic “no date.” Martin Splitt and John Mueller dodged the question like the plague. For the record, Google has tied the rollout to a publisher-rights agreement, with no timeline on the table.
And the cherry on top? On June 3, Google rolled out an AI performance report in Search Console the one that isolates your impressions inside AI Overviews and AI Mode. In France, it sits there stubbornly empty, with no feature to measure. We got the measuring stick before the thing to measure. Very Google.
So on the French front: nothing (still) to see here. Let’s look elsewhere because that’s where the day got interesting.
The real message fit in one word: agentic commerce
Walking back out of Porte de Versailles, the thing that struck me wasn’t the French saga. It was John Mueller’s insistence on a single theme: agentic commerce.
And when Mueller, who normally weighs every word to avoid promising anything, says the same thing three times, he’s not filling air. The message was clear: get your sites ready for agentic commerce, now, by leaning on the protocols Google backs. Namely WebMCP, UCP, and the whole family that comes with them.
If you take away one thing from the day, take that one.
What is agentic commerce?
Until now, an AI agent that wanted to buy on your site was duct-taping its way through: scraping your HTML, guessing where the search bar was, simulating clicks, burning thousands of tokens trying to understand your checkout funnel. In short, it read you like a short-sighted human.
The idea of agentic commerce is to replace that guesswork with structured, directly callable actions. The agent no longer infers what your “Add to cart” button does, it executes it through a declared function.
Google’s go-to scenario: a user types “red Nikes in size 9” into Gemini; the agent queries several merchants, checks stock, size and price, and closes the purchase, without anyone ever setting foot on your product page.
That’s where the next visibility battle is being fought. And that’s exactly why Mueller kept hammering it.
The agentic-commerce stack to know: WebMCP, UCP, and the rest
We’re talking about a layered stack, not a single protocol.
WebMCP: the browser layer (the “how” on your site)
Published by Google as a W3C Draft on February 10, 2026, backed by Google and Microsoft. It introduces a browser API (navigator.modelContext) that lets your site publish a list of callable tools: searchProducts, addToCart, checkout…
The agent discovers those functions and runs them directly, inheriting the browser’s session and authentication. Still in early preview, but it’s the standard to watch.
To put it simply: Schema.org structured data describes the nouns (what your products are), WebMCP describes the verbs(what you can do with them). You need both. And speaking of structured data, Splitt’s slide still recommends marking your pages up so crawlers understand them.
UCP (Universal Commerce Protocol): the commerce layer (the “what” across platforms)
Announced on January 11, 2026, co-developed with Shopify, Etsy, Wayfair, Target and Walmart, and endorsed by 20+ partners (Stripe, Visa, Mastercard, American Express, Adyen, Zalando…).
Where WebMCP handles interaction on one site, UCP standardises the full purchase journey across platforms, enabling direct buying inside Google Search’s AI Mode and Gemini.
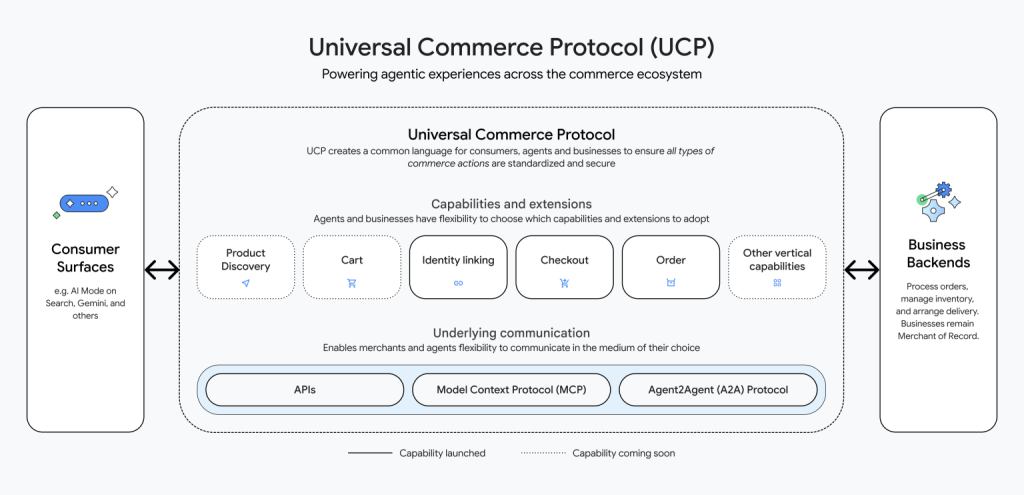
One thing to reassure the boardroom: you stay the Merchant of Record. You keep the transaction, the data and the customer relationship. Discovery happens through a simple /.well-known/ucp endpoint, on the same principle as an HTTP negotiation.
AP2, A2A, MCP: the supporting agentic protocols
AP2 (Agent Payments Protocol) handles agent payments with cryptographic proof of consent. A2A (Agent2Agent) handles agent-to-agent communication. MCP (the original protocol, from Anthropic) connects agents to server-side tools. UCP is built to interoperate with all three.
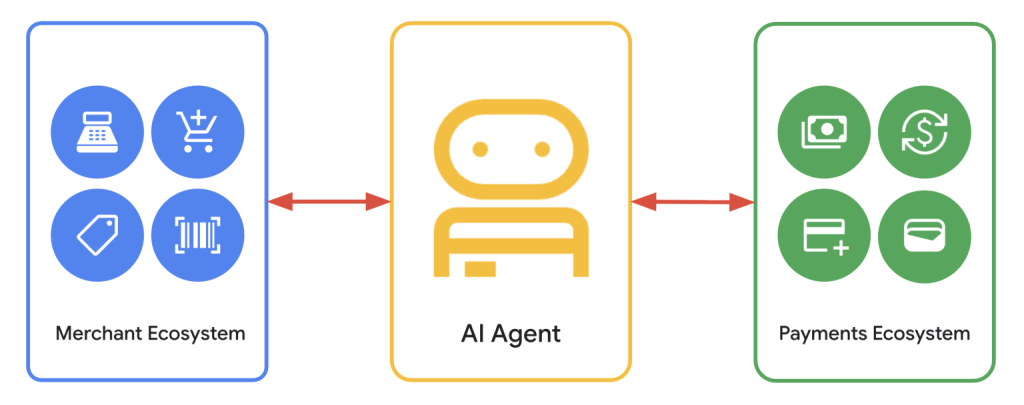
The overall logic: UCP orchestrates cross-platform commerce, WebMCP handles on-site interaction, AP2 secures payment. You don’t have to implement everything at once, but you’d better know where you sit.
What this changes for you (especially in e-commerce)
The advice Mueller has been repeating for months, and repeated in Paris, is simple: make sure your store is accessible to AI agents. Not optimised , accessible. Plenty of sites already fail at that first step.
1. Crawl, crawl, crawl
That was one of my headlines from last year’s Zurich Search Central. I’m standing by it again this year.
To give agents access, make your site crawlable and reachable by agentic experiences, Google’s, and those of any other player you choose to trust.
The Q&A example said it well: an agent lands on your store, drops a product in the cart, kicks off checkout, that’s a sale. Except a lot of sites see “a bot” and block it on reflex. Result: the agent can’t complete… and goes to try its luck at a competitor.
The concrete advice: learn to recognise legitimate agents (Google exposes a dedicated user-agent for its agentic experiences, whose IP you can validate like a crawler) and consciously decide whether to allow them, instead of blocking them all unknowingly at the robots.txt or WAF level.
2. Price / stock / feed consistency
Agents cross-check your sources. If your product page shows €49.99 and your Merchant Center feed says €59.99, the agent treats the data as unreliable and drops you. One single source of truth.
3. Rich structured data
Valid, complete Product and Offer schema, real availability, structured signalling of what’s free vs paywalled. That’s the foundation the WebMCP verbs sit on top of.
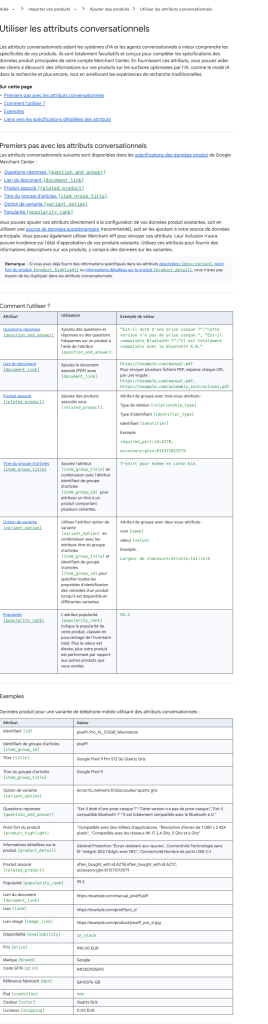
4. The Merchant Center’s new conversational attributes
Quietly added at Google Marketing Live 2026: product Q&A, Document Link (manuals, warranties), Related Product, Item Group Title, Variant Option, Popularity Rank. 100% optional, no risk to your classic Shopping campaigns. Might as well fill them in.
So French e-commerce sites are off the hook on agentic commerce?
We said it up top: all of this targets AI Mode and AI Overviews, which still don’t run here. So the temptation is to file the topic under “when it arrives.”
Wrong reflex. Don’t forget the other players, ChatGPT, Perplexity, readying their platforms for the same experience. And they’re very much live in France. So yes, French e-commerce sites are concerned too.
Canonical URLs: the technical reminder Google hammered home
Midway through “How Search Works,” Martin Splitt spent a surprisingly long stretch on something we all think we’ve nailed: canonicalisation.
The message fit in one sentence, only canonical URLs actually make it into the index. And what isn’t in the index can’t be cited in AI Overviews or AI Mode. In other words, your canonical hygiene directly gates your eligibility to show up in AI answers. It’s become a visibility issue, not just a tidiness one.
On-site: one product, ten URLs
The on-stage example was deliberately mundane, a shop with a red t-shirt reachable via /products/t-shirt/red, via /sale because it’s discounted, via ?id=123 because of the shop system, in www and non-www, in http and https… You end up with a dozen addresses pointing to the exact same content. Google picks one to index and “remembers” the others.
Let it guess, and it may pick the wrong one. The fix is classic but too often neglected: consistent rel=canonical, clean redirects on protocol and host variants, URL-parameter handling, and internal linking that always points to the canonical version. On a large e-commerce catalogue, that’s where half your crawl budget is won or lost, and make no mistake, Google has had enough: it no longer wants, and frankly no longer can, crawl everything.
Off-site: cross-domain canonicalisation
This is the part the room full of press editors needed to hear. When the same content lives on several domains, syndication to partners, pickup by an aggregator, republication, or plain scraping, Google also has to designate a canonical, but this time across sites. And here the risk changes nature: if your syndication partner publishes your article without a rel=canonical pointing back to your original, their version can become the canonical and capture the ranking (and the AI citations) for your own content.
For publishers, the rule is simple: never let content go out in syndication without a canonical (or at least a clear link) back to the source. The same reflex applies to your own multi-domain or multi-ccTLD variants.
How Search Works: how Google actually runs
The classic slide : crawl, render (headless Chrome), index and serve.

The other concept that grabbed me was Splitt’s insistence on the fluidity of Google’s index. We all treat indexing like a status you earn once: “my page is indexed, case closed.” Wrong. The index is a living organism, re-evaluated continuously, and your page can drop out of it without notice. Four truths that coexist:
- Yes, your content is indexed today. That says nothing about tomorrow: Google revisits its decisions constantly.
- Yes, your content is excellent, but if there’s better elsewhere, it can be deindexed. Excellence is relative, never absolute.
- Yes, your content is excellent, but if nobody searches for it (no volume, never served in results), it can be deindexed. No demand, no slot.
- Yes, your content is excellent, but if AI already answers the question, it becomes redundant, and a candidate for the exit.
There’s a signal worth reading in Search Console here: “Crawled – currently not indexed” is almost never a technical rendering bug. More often than not it’s a quality verdict, Google saw the page and decided it didn’t earn its place. With AI exploding the volume of content produced, Google has mechanically raised the bar for what gets indexed (selective indexing).
Commodity content vs Non-commodity content.
That’s when Splitt pulled out his new slide: Commodity content vs Non-commodity content.
- Commodity content is the “top 10 things to consider when buying running shoes” you find identical across thousands of sites, “think about your budget,” “a pricier shoe is sometimes higher quality”… Generic filler that AI produces in seconds, and will eventually produce instead of you.
- Non-commodity is the opposite: that customer whose shoes fell apart after 400 miles, which you cut open to analyse what actually happened inside. First-hand, non-replicable experience nobody else can write.

To qualify that “non-commodity,” Google laid out three clean criteria (already shown at the Toronto stop, same deck): unique (an angle, a dataset, a viewpoint others can’t easily replicate), specific (one real situation, not generic roundup rules), authentic (first-hand experience, not reworded Google results). If your page checks none of those boxes, AI does the same job in two seconds, and often better.
My take? Splitt could have just called it information gain. The concept has been climbing for months, precisely because of AI. But you’ve got to coin your own house vocabulary, I suppose. Fair enough. The idea itself is right: in a fluid index where AI absorbs everything generic, only the content you alone can produce keeps its place. (For what it’s worth, the industry agreed, at Toronto, Gianluca Fiorelli and Chris Long publicly tied the same deck back to information gain.)
GEO / LLM SEO / AEO?
For me, no debate. It’s GEO. Then again, I’m not exactly objective here…

And Google made its own feelings clear: it openly mocked the acronym inflation (GEO, AEO, LLMO, “answer engine optimization”), new, shiny labels some agencies invent mostly because new and shiny sells. The subtext was blunt: don’t pay for a magical new discipline. Good old SEO, done right, is your GEO.
How do AI Overviews and AI Mode work under the hood?
Splitt took the time to open the black box, and it’s the most useful part to understand for everyone. An AI answer isn’t one machine: it’s two, correcting each other.


1. The model is statistics, not knowledge
An LLM is trained on a mountain of text, but at its core it just recognises patterns. A name that sounds human? Probably a person. Sounds contemporary? Probably alive. Splitt’s example landed: ask it for the title of the first children’s book he supposedly wrote, and the model proudly serves up “The Chicken and the Robot”… except that book doesn’t exist. It made it up, because statistically it looks like a plausible answer. That’s the hallucination problem: pattern, not reality.
2. Grounding via the classic index
To avoid making things up, the AI system queries Google Search. It runs the query against the index, and depending on what comes back, it answers, admits it doesn’t know, or asks you a follow-up.
SEO consequence, and it’s huge: for an AI answer to cite your content, classic search has to be able to surface it. Not in the index, or not relevant enough? You don’t exist for the AI. AI Mode isn’t searching a parallel universe, it leans on the same index you’ve been working for fifteen years.
3. Query fan-out: one question explodes into dozens
This is the key mechanism. The AI doesn’t generate one query, it fires off a whole series in the background.
Splitt’s example: “I want to buy a dive computer.” The system fans that out into sub-queries, beginner-friendly dive computer, budget options, high-end options, differences between models, pitfalls to avoid for a first purchase… as many Google searches as it runs on your behalf.
Impact of AI Overviews and AI Mode on search and visibility : Google’s view
More context, more breadth, and above all more sources pulled in than a single blue link. And since the user no longer needs to break their thinking into keywords, they search more, and ask more complex questions. More queries, more slots: more chances to show up.
The conclusion Splitt draws lines up with the tagline we know: good SEO is good GEO. The technical base (being crawlable, indexable) stays the non-negotiable prerequisite; content quality makes the difference. And one interesting side effect he flagged: by exploring through successive questions, the user sees certain brands come back again and again, and starts building a relationship with them before even clicking. The opportunities aren’t just yesterday’s blue links anymore.

A caveat from me, though: this is unmistakably the official Google line. AI Overviews and AI Mode are supposedly loved by users; they supposedly have no negative impact on impressions or clicks, quite the opposite, they encourage people to search more. What’s played down is that more and more of those searches happen directly inside the AI interfaces. De facto, fewer people click the traditional blue links. But then again, it’s a Google spokesperson at a Google conference. Hard to expect a different narrative.
Preferred sources: the anti-spam weapon Google handed to users
Splitt slipped this one in almost in passing, but it’s one of the most strategic moves of the year. Under the “convenience feature” hides a real lever, and, to my mind, an anti-spam measure that won’t say its name.
How Preferred sources work
Any user can set you as a preferred source, from the star in Top Stories or via google.com/preferences/source. Your content then shows up more often and higher in Top Stories, Discover, and, since May 27, 2026, inside AI Overviews and AI Mode, with a “preferred source” badge visible right in the AI answer. Splitt put it plainly: the relationship you already have with your readers is now carried into search, which wasn’t the case before. And you can prompt it, a simple “make us your preferred source” button does the job.
The numbers on Preferred sources

Over 345,000 sources already selected (roughly 4× the December 2025 level), and above all: a preferred source is clicked about twice as often as an equivalent link. In a world where organic CTR is collapsing under AI Overviews, that multiplier is no footnote.
Preferred sources : the new ranking factor?
Not a universal ranking factor, per Daniel Waisberg. Racking up preferred-source labels doesn’t lift your site for everyone. It’s a personalised signal, it only plays for users who already chose you. You’re not widening your audience, you’re locking in the one you already have.
Preferred sources : an anti-spam measure?
This is where it gets clever. By letting users curate their own sources, Google quietly outsources part of its anti-spam fight. Rather than adjudicating alone, algorithmically, which content deserves trust, it lets the audience surface the reliable sources, and, mechanically, bury the rest: content farms, pop-up-ridden sites, AI slop in general. Intrusive ads become a reputation poison: nobody stars a site that screams at them with banners and interstitials. Ad-bloated mass media lose; lean, expert sources win.
How to set up Preferred sources
Eligibility: any site publishing fresh content (no longer press-only), at the domain or sub-domain level, not sub-directories. You need to be properly indexed, compliant with the guidelines, with clean structured data. No manual application: it’s algorithmic.
The deep link to share: google.com/preferences/source?q=yourdomain.com , one click, the domain is pre-filled. Google even provides official buttons in 16 languages.
Where to place it: at the end of a strong article, in a newsletter footer, in the author bio. Never in the homepage hero, the urge to engage peaks right after reading something good, not before.
How to know how many users picked you: no native metric (Waisberg admitted in Q&A the team is thinking about it). In the meantime, a GA4 custom event on the CTA click, plus tracking Top Stories / Discover impressions as a proxy.
The link to the previous section is direct: non-commodity content attracts the reader, preferred-source status retains them inside AI answers.
The “Highly Cited” tag: Google makes citation visible, and it’s huge
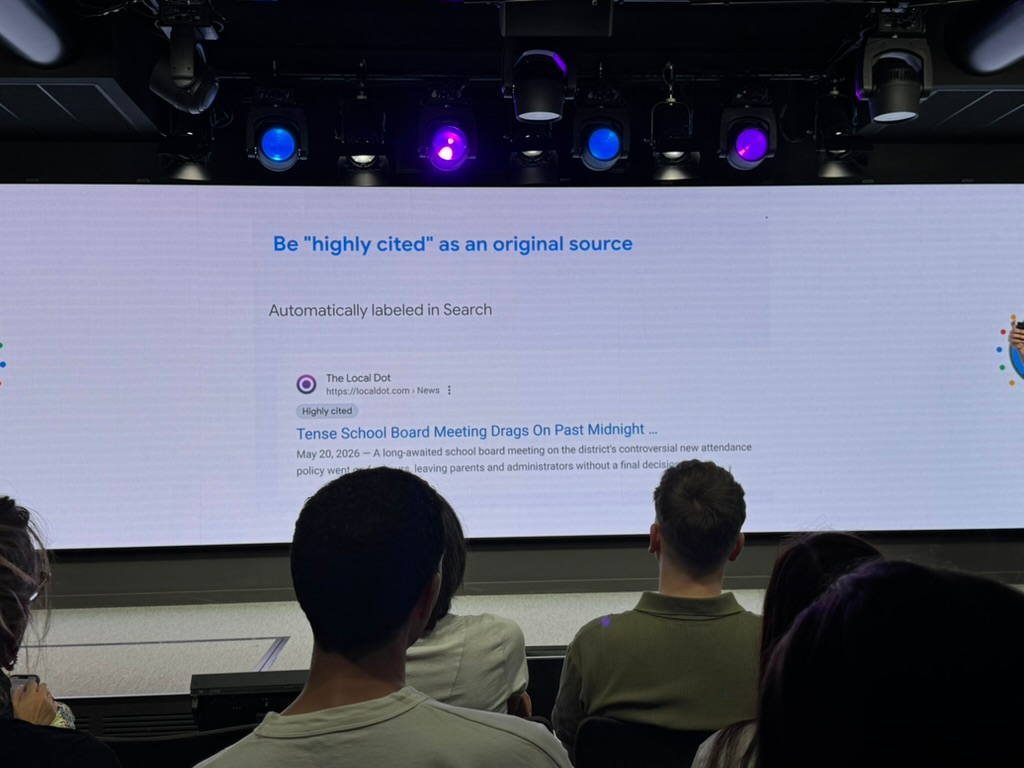
In the same wave of announcements, Google shipped the other piece of the puzzle, and this one’s underrated: the expansion of the “Highly Cited” badge.
The label isn’t new, it’s existed since 2022 in Top Stories, but on May 27, 2026, Google expanded it to far more web links in the results, and added an indicator when an article itself references a Highly Cited source. In short, it’s breaking out of its press niche to become a SERP-wide trust signal.
What the Highly Cited tag does
It flags the article others cite, the primary source behind a story, the one everybody picks up. Concretely: you write the investigation, twenty other sites paraphrase it, and you carry the badge. For once, the credit flows back to the author of the information, not to those who copy it.
How to earn the Highly Cited tag
No application, no setting: it’s algorithmic, based on how often other publishers (especially media, on original reporting) reference and link to you. In other words, it’s the old editorial-backlink signal… made visible to the user as a credibility badge.
Why the Highly Cited tag matters
Two reasons, to my mind. First, it’s Google’s anti copy-paste weapon: at a time when AI slop recopies and rewords everyone else’s work, the label tries to route credit back to the original source. Second, and this is the real story: AI shifts the game from page ranking to source authority. In an answer engine, what matters isn’t only “does my page rank?” but “am I the source everyone cites?“, because that’s exactly what AI systems reward when they assemble an answer. The Highly Cited badge is that authority made legible, both to the user and as a signal of the originality AI surfaces favour.
Per Search Engine Land, the badge expansion runs across the SERP and is not specific to AI Mode or AI Overviews, so it’s not (yet) a badge that shows up inside the AI answer itself. But the logic is pure AI-era, and it extends everything we’ve just said: preferred sources mobilise your audience, Highly Cited certifies your authority among your peers. Both converge on the same idea, becoming the source people cite and choose.
For SEOs and publishers, the to-do is crisp: original reporting, proprietary data, studies, interviews, content so singular that others have to cite you. It’s the commodity-content point taken from the other end: not only does generic content drop you out of the index, original content earns you a badge that sets you apart inside it.
Subscription Linking (Reader Revenue Manager): +34% engagement, but not an SEO win
The last lever on the publisher side, and this one targets subscription sites specifically: Subscription Linking via the Reader Revenue Manager (RRM). Splitt dropped a number that raised some eyebrows in the room: +34% engagementfor users who bring their subscription into search.
The problem it solves. A paywall creates a blind spot: your subscriber already pays, but from a search result they can’t tell which articles their subscription covers. So they can hit a wall they’ve already paid to get past. Subscription Linking lets that reader link their subscription to their Google Account; in return, a “From your subscriptions” panel appears in Google Search, Discover and News, surfacing the content they’re entitled to. Subscribers who came in through “Subscribe with Google” are included automatically.
The number, properly attributed. The +34% comes from the Indian Express case: +34% pageviews per linkedsubscriber over three months, versus just 9% for unlinked ones. News Corp Australia reports a similar lift (~30%). These are retention numbers, not acquisition, which is the whole point.
The trap not to fall into. This is not a ranking signal. The “From your subscriptions” panel is a personalised surface, visible only to subscribers who took the step of linking their account. A random visitor, a non-subscriber, an unlinked subscriber: all see the exact same SERP as before. It earns you zero organic positions and brings no new readers. It’s a retention tool, not discovery, let alone SEO. File it under “churn / retention,” not “growth.”
The technical reality. Subscription Linking is restricted to the Enterprise tier of RRM. Expect a real dev project: integrating the swg.js library, a Google Cloud project, server-side entitlement sync, and structured data on gated content (isAccessibleForFree + product IDs). That last point overlaps with the paywall question asked in the Q&A: the structured markup distinguishing free from paid mainly serves to protect your visibility (avoid being taken for cloaking when Google sees the full content while the user is blocked), not to boost a ranking.
Who’s it for? The value scales with your existing subscriber base: a title with tens of thousands of linked subscribers has plenty to feed the panel; a new site with three subscribers has almost nobody to show up for. The logic is exactly that of preferred sources, you extend an existing relationship into search, you don’t create a new one. Two sides of one coin: the reader chooses you (preferred source) or pays you (subscription linking), and Google carries that relationship right into the SERP.
The AI Mode top keywords: explain, find, identify, summarize

A slide I snapped is worth a whole intent audit: the keywords that dominate AI Mode searches. The lineup? Explain, Find, Information, Identify, Summarize. Look closely, these aren’t navigational queries or product keywords. They’re cognitive verbs. The user no longer types “best CRM 2026”; they ask the AI to explain, identify, summarise, find the information for them.
Direct consequence for your content: it has to be explainable, summarisable, identifiable. A page that cleanly answers “explain X to me,” “identify the differences between Y and Z,” “summarise the options” stands a far better chance of being pulled into an AI answer than an old-school wall of optimised text. Structure for synthesis: clean definitions, explicit comparisons, direct answers at the top of each section. The AI is looking for blocks it can cite, not paragraphs it has to dismantle.
Measuring your visibility in the GEO era: Trends + Search Console
Measurement was the day’s other thread, and one slide summed up the approach: cross-reference two complementary data sources. On one side, Google Trends, Terms, Topics, Geo, Interest: demand, what people search for, where, with what momentum. On the other, Search Console, Queries, Pages, Geo, Impressions, Clicks, Position: your real performance, what you actually capture.

The hinge is Geo, present in both: it lets you overlay a territory’s demand with your visibility on it, to spot the blind spots (high demand, low presence). With CTR collapsing under AI Overviews and part of the traffic going invisible, this demand/performance cross-check becomes the baseline reflex again. Google’s reminder: stop reading impressions and clicks in isolation; read the gap between what the market wants and what you serve. And for fine analysis, favour the BigQuery export / the API over the more limited interface.
Two Search Console novelties worth knowing, from Waisberg. First, Query Groups: instead of drowning in thousands of individual queries, the GSC now clusters them by theme (grouped by meaning, via AI, not by character string), no more intent split across a hundred variants, typos and languages. Second, natural-language configuration: you describe the report you want in one sentence, and Gemini builds it for you, no manual filter-wrangling. Two real time-savers, and one more sign the GSC is becoming an AI-driven tool.
Discover: the real French playground
While AI Overviews keep us waiting, Discover remains the most powerful AI-adjacent surface available to French publishers. Three slides made the case.
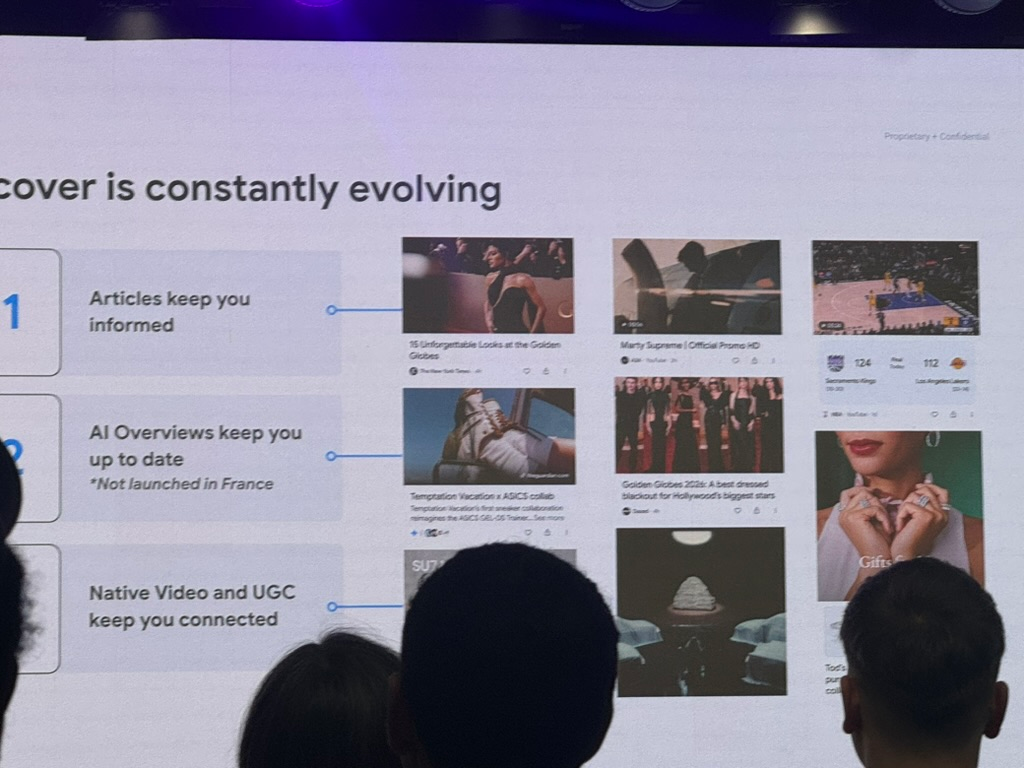
1. Discover keeps evolving. The “Discover is constantly evolving” slide lays out three roles: articles keep you informed, AI Overviews keep you up to date, with, again, the asterisk that stings: “Not launched in France”, and native video + UGC keep you connected. Translation: Discover is going multi-format. If you bet everything on text articles, you’re playing on a third of the field; native video and creator content are taking up more and more room.

2. Trust & Safety keeps watch. Shivani Gupta (Trust & Safety) showed the underlying machinery: a Partner Compliance ↔ Proactive/Reactive Content Reviews cycle. Behind the editorial promise sits an enforcement layer, partner compliance and content reviews, both proactive and reactive. It’s Discover’s anti-AI-slop arm: your eligibility depends as much on policy compliance as on perceived quality. One slip, and you drop out of the feed.

3. The Core Update favours expertise. The most telling slide for SEOs: “Core Update: why we surface expertise.”Three columns
- Purpose: ensure credible, trustworthy, expert reporting;
- Process: Discover measures publisher authority to distinguish relevant, accurate reporting from low-quality content;
- Benefit: deliver in-depth, original, timely content. Note the exact phrase: Discover measures publisher authority. That’s E-E-A-T said without euphemism, and it’s the through-line of the whole day, the one connecting Highly Cited, commodity content and preferred sources: source authority has become the product.
The Q&A: what Google did (and didn’t) want to answer






The Q&A ran on questions submitted in advance through a form, and Google set the ground rule up front, a tasty one: any question starting with “when…” was dropped. “If we had something to announce, we’d have announced it.” So much for the calendar. For the rest, the answers worth the detour.
AI in the editorial workflow: how far can you go?
Google doesn’t care how the content is made; it looks at what’s published. Lots of AI to produce excellent content: fine. A bit of AI plus scripting to pump out 1,000 pages a day: a liability. Useful reminder, low-effort didn’t wait for AI: a human produces empty content perfectly well.
And if I pivot to low-cost to keep up the pace?
Mueller’s answer is chilling, and it ties back to index fluidity: site-level quality signals take time to update. If you degrade your content, a quality update will eventually label your site “low quality overall”, and then the drop (search and Discover) can take several months, sometimes over a year to recover. It’s not a 404 you fix: no Googler “repairs” a reputation by hand. Better to avoid than to cure.
Why only 16 months of history in Search Console?
To allow year-over-year quarter comparisons (15 months + 1 to analyse). Beyond that, it’s a trade-off with interface speed (10 years of data = reports that take minutes to load). Only ~2% of users want more. Otherwise, export (API, BigQuery, or third-party tools that pour the GSC into a Sheet), and use the Search Console feedback function; they read it and act on it.
Why don’t my GSC numbers ever add up when I filter?
The culprit: sampling. Each filter applies sampling; filter twice and you’re sampling on top of sampled data → the chart shows 20,000 clicks, the table sums to 10,000. The single fix: BigQuery export, far more complete than the UI and the API (which hits already-compressed data). Storable up to ~100 months, it costs, warn finance.
Sponsored content / advertorials: what markup?
No specific label on the search side. The essential: tag sponsored links with the normal attribute (rel="sponsored"). You can block indexing, it’s not mandatory. Google News and Discover may differ.
An API to push my content straight to Google (MCP & co)?
The answer resets expectations: crawling isn’t the bottleneck, Google’s real problem is recognising good content. If it can spot it, classic crawling is enough to surface it. The Indexing API exists, but it’s reserved for very volatile content (news, video, job postings). A general-purpose “upload” API? Maybe one day, not the priority.
How to identify and prioritise low-volume, high-value B2B queries?
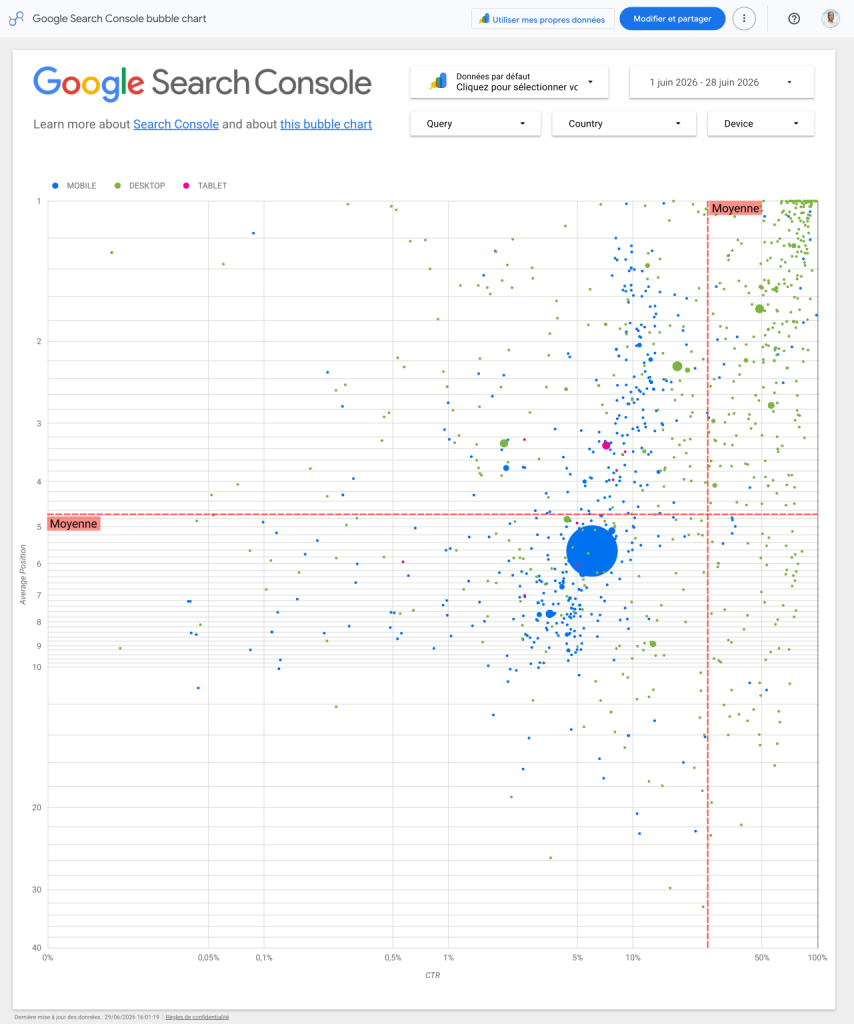
The session’s actionable gem (with a Google template to boot: developers.google.com/search/docs/monitor-debug/bubble-chart-analysis). Each bubble = a keyword, size = clicks, colour = device. The zone to work: mid-range position but high CTR, the people who see them click, so gaining a position or two yields a disproportionate payoff. That’s where your editorial effort goes, not on keywords already at the top.
A few other questions, paywall configuration (all equivalent on the search side), preferred-source stats, agentic access to secure first, markdown/llms.txt, got answers already detailed above. Google was remarkably consistent from end to end: content quality, technical fundamentals, patience on AI.
One detail to close the day: John Mueller ran the entire Q&A remotely, from the United States, not even around for the after-drinks, as the host teased.
Markdown, llms.txt, GEO: should you panic? Splitt and Mueller say no
If there’s one ground where the Googlers deliberately cooled things down, it’s the race for formats and new acronyms. And here, Splitt and Mueller held exactly the same line: for now, it doesn’t change much.
File format? Irrelevant. Splitt illustrated it with his own diary, which he saves as Markdown, “it could be HTML, a plain text file, doesn’t matter.” On Google’s side, no preference between MD, HTML and TXT. Format isn’t a visibility lever.
llms.txt? Yes, Lighthouse now detects it, and Google’s docs concede it “can be useful” but read between the lines. That’s mostly Google politely answering “yes, you can” to a question it gets asked on loop. It’s neither a recommendation nor a factor. Nobody on stage said “deploy llms.txt and you’ll gain something.”
The clincher, from Mueller. Generating a markdown version of a page is trivial: copy the page into Google Docs, export as markdown, done. So no need to prepare it in advance. If one day an agent only consumes markdown, you’ll produce it in two minutes, there’s no first-mover bonus. The repeated watchword: “it’s okay to wait.” Don’t optimise for “the five AI geeks in the room” until real users are there.
The anti-hype kicker. Splitt couldn’t resist a jab at acronym inflation: GEO, AEO, LLMO, “answer engine optimization”… brand-new initialisms some agencies invent mostly because new and shiny sells. The subtext was unmistakable: don’t pay for a miracle new discipline. Good old SEO, done right, is your GEO.
Bottom line on this front: keep your budget. Fundamentals plus great content, and you’ll generate the markdown the day an agent actually needs it.
Google Search Console Paris recap
If you only read one section, read this. The whole day boiled down to one shift: we’re moving from a page-positioning game to a source-authority game. In an answer engine, the question is no longer “does my page rank?” but “am I the source the system cites, the reader chooses, and my peers reference?” Everything else follows.
Do now (real impact, calendar-agnostic):
- Lock down index eligibility. Crawlability, clean canonicals (on-site and cross-domain), no duplication that dilutes. What isn’t in the index can’t be cited by AI. That’s the prerequisite, full stop.
- Get out of commodity. Audit your editorial catalogue: anything AI churns out in 30 seconds is on borrowed time in a fluid index. Reallocate toward first-hand, proprietary data, original analysis, the content that deserves citation (and earns the Highly Cited badge).
- Secure agentic access. The only genuinely urgent “agentic” job: make sure robots.txt / WAF / firewall don’t reflexively block legitimate agents, especially in e-commerce, where the agent that checks out is a sale. Conscious decision, not accidental block.
- Wire measurement to GEO reality. BigQuery by default (the UI samples, the API hits compressed data). Cross demand (Trends) and performance (GSC), read the market/offer gap rather than isolated impressions and clicks, and instrument what’s no longer clicked (conversions, brand, long queries).
- Activate audience levers without selling them as ranking. Preferred sources (deep link at the end of articles and in newsletter footers) and, for publishers, subscription linking. These are retention levers, not acquisition or ranking. Present them as such internally.
Watch (monitor, don’t budget):
- The agentic-commerce stack (WebMCP / UCP / AP2): real and Google-backed, but in preview. Know where you sit; implement only if your e-commerce model already justifies it.
- AI Mode when it lands in France: demand structure shifts (cognitive verbs explain / find / identify / summarize, query fan-out). Structure for synthesis now, it also serves classic SEO.
- Discover, the No. 1 AI-adjacent surface available in France: multi-format (native video, UGC), driven by editorial authority and Trust & Safety compliance.
In summary
Google didn’t drop a date for AI Overviews and AI Mode in France, but it gave us a taste of what’s coming: agentic commerce is no longer prospective, it’s the work already under way. WebMCP on the site side, UCP on the platform side, AP2 on the payment side: the stack is laid, the partners are there. Just keep one nuance in mind, Mueller said “don’t wait” on access and fundamentals, but “it’s okay to wait” on protocols, markdown and llms.txt.
The good news: the entry ticket is nothing esoteric, a clean crawl, consistent feeds, solid structured data. Foundational tech SEO. The same hygiene as before, applied to a new kind of buyer, one that this time isn’t human.
Good GEO is good SEO. And soon, good agentic commerce too.
- Google Search Central Live Paris 2026: Google Is Betting on Agentic Commerce
- AI Overviews and AI Mode in France: Google Confirms It’s Coming (Updated June 24, 2026)
- VivaTech 2026 through a SEO/GEO lens: who was there, who wasn’t, and the rise of “bad AI”
- Google Search Central Live Paris: what to expect on June 25
- Google’s Geo checklist: how to optimize your site for AI agents ?
Leave a Reply
You must be logged in to post a comment.