
Le 25 juin, Google posait pour la première fois son Search Central Live à Paris, la toute première édition française, ouverte en français par Faten Dubary (Director, News Partnership France-MEA) devant plus de 200 personnes : éditeurs de presse, groupes médias, SEO et développeurs. Avant de parler de ce qui m’a vraiment marqué sur cette journée, il faut crever l’abcès, parce que c’est la question que tout le monde se posait en entrant dans la salle.

AI Overviews et AI Mode en France : toujours aucune date au Search Central Live Paris 2026
Grosse déception : Google n’a rien annoncé sur l’arrivée des AI Overviews et de l’AI Mode en France. Rien. Et ce, malgré les rumeurs qui se succedent…
La communauté française a poussé, forcément. Mais la réponse est toujours la même : le grand classique du « aucune date »… Martin Splitt et John Mueller ont esquivé la question comme la peste…
Le vrai message de Google tenait en un mot : l’agentique
En repartant de Porte de Versailles, ce n’est pas le serpent de mer français qui m’a marqué. C’est l’insistance de John Mueller sur un seul thème : le commerce agentique.
Et quand Mueller, qui d’habitude pèse chaque mot répète trois fois la même chose, ce n’est pas pour meubler. Le message était clair : préparez vos sites au commerce agentique, dès maintenant, en vous appuyant sur les protocoles soutenus par Google. A savoir : WebMCP, UCP, et toute la famille qui va avec…
Si vous ne deviez retenir qu’une chose de cette journée, c’est celle-là.
C’est quoi le commerce agentique ?
Jusqu’ici, un agent IA qui voulait acheter sur votre site faisait du bricolage : il scrapait votre HTML, devinait où était la barre de recherche, simulait des clics, brûlait des milliers de tokens à essayer de comprendre votre tunnel de commande. Bref, il vous lisait *comme un humain myope*.
L’idée du commerce agentique, c’est de remplacer cette devinette par des actions structurées et appelables directement. L’agent ne suppose plus ce que fait votre bouton « Ajouter au panier » : il l’exécute via une fonction déclarée.
Le scénario type que Google met en avant : un utilisateur tape « des Nike rouges en 42 » dans Gemini, l’agent interroge plusieurs marchands, vérifie le stock, la taille, le prix, et boucle l’achat, sans que personne ne mette jamais les pieds sur votre fiche produit.
C’est là que se joue la prochaine bataille de visibilité. Et c’est exactement pour ça que Mueller insistait.
Le stack commerce agentique à connaître : WebMCP, UCP, et le reste
On parle d’une pile en couches, pas d’un seul protocole.
WebMCP : la couche navigateur (le « comment » sur votre site).
Publié par Google en W3C Draft le 10 février 2026, soutenu par Google et Microsoft. Il introduit une API navigateur (`navigator.modelContext`) qui permet à votre site de publier une liste d’outils appelables : `searchProducts`, `addToCart`, `checkout`…
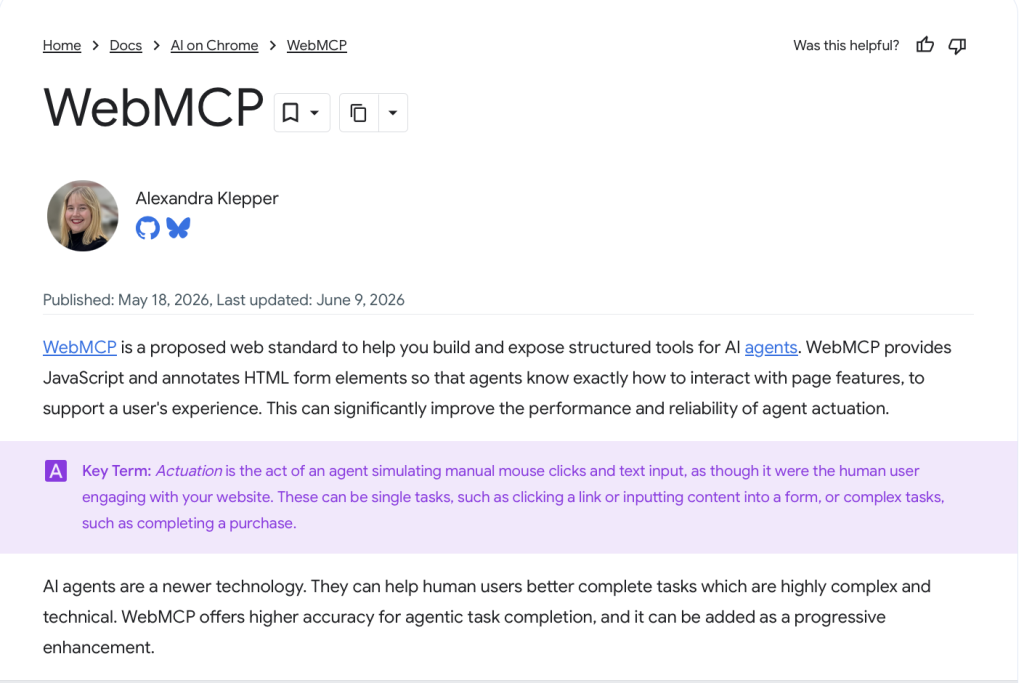
L’agent découvre ces fonctions et les exécute directement, en héritant de la session et de l’authentification du navigateur. Encore en early preview, mais c’est le standard à surveiller.
Pour simplifier un peu, les données structurées Schema.org décrivent les noms (ce que sont vos produits), WebMCP décrit les verbes (ce qu’on peut faire avec). Les deux sont nécessaires.
En parlant de données structurées, ces dernières ont été abordées. Martin Splitt dans un slide recommande toujours les micros données pour aider les crawlers à comprendre le contenu de vos pages.
UCP (Universal Commerce Protocol) : la couche commerce (le « quoi » entre plateformes).
Annoncé le 11 janvier 2026, co-développé avec Shopify, Etsy, Wayfair, Target et Walmart, et endossé par 20+ partenaires (Stripe, Visa, Mastercard, American Express, Adyen, Zalando…).
Là où WebMCP gère l’interaction sur un site, UCP standardise le parcours d’achat complet entre plateformes pour permettre l’achat direct dans l’AI Mode de Google Search et dans Gemini.
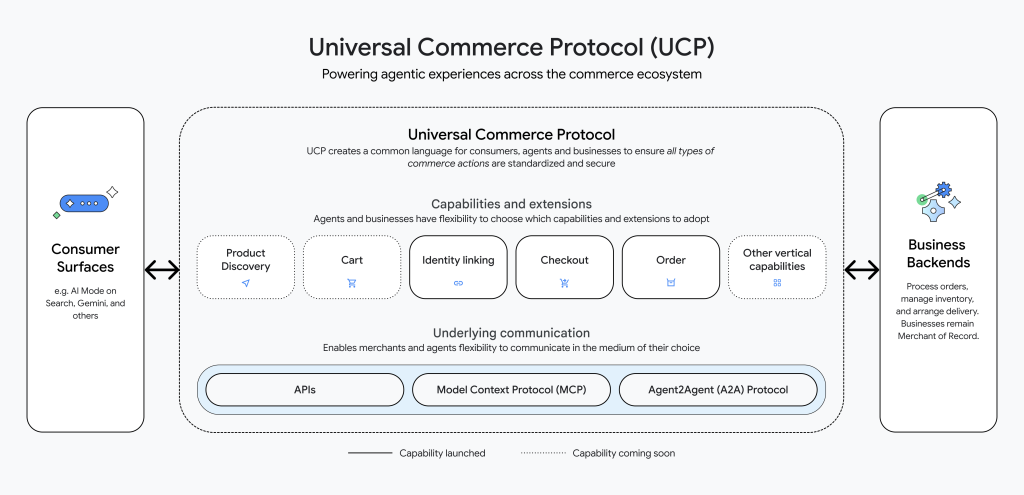
PS : vous restez Merchant of Record. Vous gardez la transaction, les données et la relation client. La découverte se fait via un simple endpoint `/.well-known/ucp`, sur le même principe qu’une négociation HTTP.
AP2, A2A, MCP, les protocols agentiques supports.
AP2 (Agent Payments Protocol) gère le paiement par les agents avec preuve cryptographique du consentement. A2A (Agent2Agent) gère la communication entre agents. MCP (le protocole d’origine, signé Anthropic) connecte les agents aux outils côté serveur. UCP est conçu pour être interopérable avec les trois.
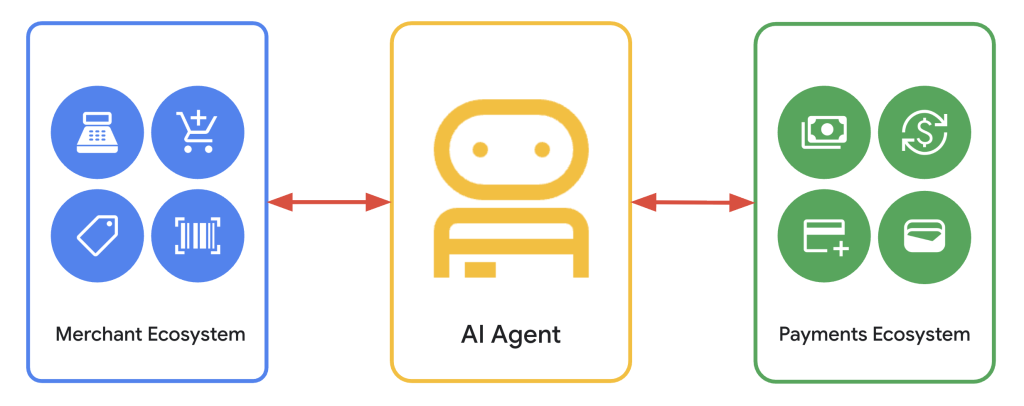
La logique d’ensemble : UCP orchestre le commerce inter-plateformes, WebMCP gère l’interaction sur votre site, AP2 sécurise le paiement. Vous n’avez pas à tout implémenter d’un coup, mais vous avez intérêt à savoir où vous vous situez.
Ce que ça change pour vous (surtout si vous faites du e-commerce)
Le conseil que Mueller martèle depuis quelques mois, et qu’il a redit à Paris, est simple : vérifiez que votre boutique est accessible aux agents IA. Pas optimisée, mais Accessible. Beaucoup de sites échouent déjà à cette première étape.
Comment rendre son site accessible pour les agents ?
1. Le crawl, le crawl, le crawl
C’était un de mes titres du search central de Zurich l’année passée. Et je le maintiens pour cette année aussi.
Pour donner l’accès aux agents, rendez votre site crawlable et accessible aux expériences agentiques, celles de Google comme celles des autres acteurs que vous choisissez de faire confiance.
L’exemple donné en Q&A est parlant : un agent arrive sur votre boutique, met un produit au panier, lance le checkout, c’est une vente, sauf que beaucoup de sites voient « un bot » et le bloquent par réflexe. Résultat : l’agent ne peut pas finaliser… et il va tenter sa chance chez le concurrent.
Le conseil concret : apprenez à reconnaître les agents légitimes (Google expose un user-agent dédié pour ses expériences agentiques, dont vous pouvez valider l’IP comme un crawler) et décidez consciemment de les autoriser ou non — au lieu de tous les bloquer sans le savoir au niveau du robots.txt ou du WAF.
2. Cohérence prix / stock / feed.
Les agents recoupent vos sources. Si votre fiche produit affiche 49,99 € et que votre flux Merchant Center dit 59,99 €, l’agent considère la donnée comme non fiable et vous écarte. Une seule source de vérité.
3. Données structurées riches.
Schema `Product` et `Offer` valides et complets, disponibilité réelle, signalement structuré de ce qui est gratuit vs payant (paywall). C’est le socle sur lequel les verbes WebMCP viendront se poser.
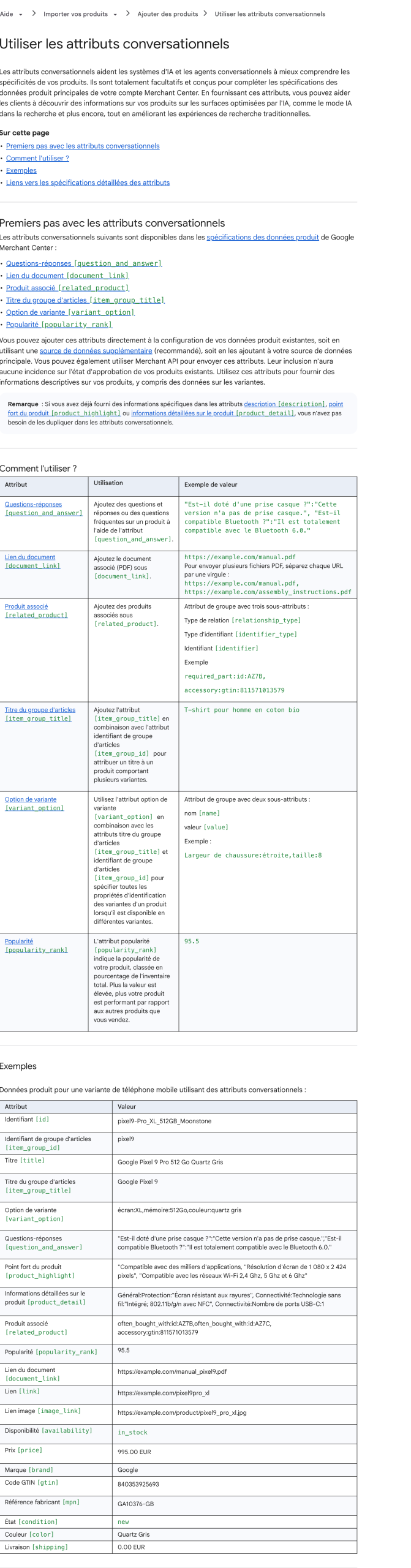
4. Les nouveaux attributs conversationnels du Merchant Center.
Discrètement ajoutés au Google Marketing Live 2026 : Q&A produit, Document Link (manuels, garanties), Related Product, Item Group Title, Variant Option, Popularity Rank. 100 % optionnels, sans risque pour vos campagnes Shopping classiques. Autant les renseigner.
Les sites e commerces français ne sont pas concernes par le commerce agentique ?
On l’a dit en intro : tout ça vise l’AI Mode et les AI Overviews, qui ne tournent toujours pas chez nous. La tentation est donc de remettre le sujet à « quand ça arrivera ».
Mauvais réflexe. N’oublions pas les autres acteurs a savoir ChatGPT, Perplexity, qui préparent leurs plateformes pour l’experience. Et qui sont bel et bien disponibles en France.
Les sites e-commerces français sont donc concernés.
URL canonique : le rappel technique de Google
Au milieu du « How Search Works », Martin Splitt a passé un temps étonnamment long sur un sujet qu’on croit tous maîtriser : la canonicalisation.
Le message tenait en une phrase, seules les URL canoniques entrent réellement dans l’index. Or ce qui n’est pas dans l’index ne peut pas être cité dans les AI Overviews ou l’AI Mode.
Autrement dit, votre hygiène de canonical conditionne directement votre éligibilité à apparaître dans les réponses IA. C’est devenu un sujet de visibilité, plus seulement de propreté technique.
Le volet on-site : un produit, dix URL.
L’exemple donné sur scène était volontairement banal, une boutique avec un t-shirt rouge accessible via `/produits/t-shirt/rouge`, via `/soldes` parce qu’il est en promo, via `?id=123` à cause du système de boutique, en `www` et en non-`www`, en `http` et en `https`… On se retrouve avec une dizaine d’adresses pointant vers exactement le même contenu. Google en choisit une seule à indexer et se souvient des autres.
Si vous le laissez deviner, il peut élire la mauvaise. La parade est classique mais trop souvent négligée. `rel=canonical` cohérent, redirections propres sur les variantes de protocole et de hôte, gestion des paramètres d’URL, et maillage interne qui pointe toujours vers la version canonique.
Sur un gros catalogue e-commerce, c’est là que se gagne ou se perd la moitié du budget de crawl. Et on l’a compris, Google en a assez. Ils ne veulent, ils ne peuvent plus, tout crawler…
Le volet off-site : la canonicalisation entre domaines.
C’est le point que la salle d’éditeurs de presse devait entendre. Quand le même contenu vit sur plusieurs domaines : syndication vers des partenaires, reprise par un agrégateur, republication, ou simple scraping, Google doit aussi désigner un canonique, mais cette fois à travers les sites. Et là, le risque change de nature : si votre partenaire de syndication publie votre article sans `rel=canonical` qui pointe vers votre original, c’est sa version qui peut devenir la canonique et capter le classement (et les citations IA) sur votre propre contenu.
Pour les médias, la recommandation est simple, ne laisser jamais partir un contenu en syndication sans canonical (ou a minima un lien clair) renvoyant vers la source. Le même réflexe vaut pour vos propres déclinaisons multi-domaines ou multi-ccTLD.
Après, s’ils ont aussi parlé de canonicalisation, j’ai l’impression qu’ils ont besoin d’un coup de main. Ils cherchent à faire référencer l’URL d’origine par les solutions d’IA, mais seulement lorsqu’elles décident de la citer.
How Search works ? Comment fonctionne Google !
Le slide typique ou ca parle de crawl, render (Chrome headless), index et serve.

L’autre concept qui m’a accroché, c’est l’insistance de Martin Splitt sur la fluidité de l’index de Google. On traite tous l’indexation comme un statut acquis : ma page est indexée, dossier classé. Faux. L’index est un organisme vivant, réévalué en continu, et votre page peut en sortir sans préavis. Quatre vérités qui cohabitent :
- Oui, votre contenu est indexé aujourd’hui. Ça ne présage rien de demain : Google revisite ses décisions en permanence.
- Oui, votre contenu est excellent, mais s’il en existe un meilleur ailleurs, il peut être désindexé.
- Oui, votre contenu est excellent, mais si personne ne le cherche (aucun volume, jamais servi en résultats), il peut être désindexé. Pas de demande, pas de place.
- Oui, votre contenu est excellent, mais si l’IA répond déjà à la question, il devient redondant, et candidat à la sortie.
Ps : sur Search console : le statut « Explorée, actuellement non indexée » n’est presque jamais un bug technique de rendu. C’est le plus souvent un verdict de qualité, Google a vu la page et a jugé qu’elle ne méritait pas sa place. L’IA ayant fait exploser le volume produit, Google a mécaniquement relevé la barre de ce qui entre dans l’index (selective indexing).
Commodity content vs Non-commodity content.
C’est là que Splitt a dégainé son nouveau slide : Commodity content vs Non-commodity content.
- Le commodity content, c’est le « top 10 des critères pour choisir ses chaussures de running » qu’on retrouve à l’identique sur des milliers de sites « pensez à votre budget », « une chaussure plus chère est parfois de meilleure qualité »… Du vide générique, que l’IA produit en quelques secondes et finira par produire à votre place.
- Le non-commodity, c’est l’inverse : ce client dont les chaussures ont lâché après 400 km, qu’on ouvre en deux pour analyser ce qui s’est réellement passé à l’intérieur. De l’expérience de première main, non réplicable, que personne d’autre ne peut écrire.

Mon avis ? Splitt aurait pu appeler ça information gain. Le concept monte depuis quelques mois, précisément avec l’IA. Mais il fallait bien inventer son propre vocabulaire maison. Pourquoi pas. L’idée, elle, est juste : dans un index fluide où l’IA absorbe tout ce qui est générique, seul le contenu que vous êtes le seul à pouvoir produire garde sa place.
Critères d’un contenu non-commodity
Pour qualifier ce non-commodity content, Google a posé trois critères (déjà montrés à Toronto, même deck) :
- unique (un angle, une donnée, un point de vue difficilement réplicable),
- spécifique (une situation réelle, pas des règles génériques façon top 10
- authentique (de l’expérience de première main, pas du résultat Google reformulé). Si votre page ne coche aucune de ces cases, l’IA fait le même travail en deux secondes, et souvent mieux.
GEO / LLM SEO / AEO ?
Pour moi, y a pas débat. C’est GEO. Après, je ne suis pas très objectif, hein…

Comment fonctionnent les AI Overviews / IA mode sous le capot ?


Splitt a pris le temps d’ouvrir la boîte noire, et c’est la partie la plus utile à comprendre pour tout le monde. Une réponse IA, ce n’est pas une seule machine : c’en est deux, qui se corrigent l’une l’autre.
1. Le modèle, c’est des statistiques, pas du savoir.
Un LLM est entraîné sur une montagne de texte, mais au fond il ne fait que reconnaître des motifs. Un nom qui sonne humain ? Probablement une personne. Qui sonne contemporain ? Probablement vivant. L’exemple de Splitt était parlant : demandez-lui le titre du premier livre pour enfants qu’il aurait écrit, et le modèle vous sort fièrement *« Le Poulet et le Robot »*… sauf que ce livre n’existe pas. Il l’a inventé, parce que statistiquement ça ressemble à une réponse plausible.
2. L’ancrage (grounding) par l’index classique.
Pour éviter d’inventer, le système IA interroge Google Search. Il lance la requête dans l’index, et selon ce qui remonte, il répond, admet qu’il ne sait pas, ou vous repose une question.
Conséquence SEO : pour qu’une réponse IA cite votre contenu, il faut que la recherche classique puisse le faire remonter. Pas présent dans l’index, ou pas assez pertinent ? Vous n’existez pas pour l’IA. L’AI Mode ne va pas chercher dans un univers parallèle : il s’appuie sur le même index que vous travaillez depuis quinze ans.
3. Le query fan-out : une question qui explose en dizaines.
C’est le mécanisme clé. L’IA ne génère pas une requête, elle en lance toute une série en arrière-plan.
L’exemple de Splitt : « je veux acheter un ordinateur de plongée. » Le système éclate ça en sous-requêtes : ordinateur de plongée pour débutant, options économiques, options haut de gamme, différences entre les modèles, pièges à éviter pour un premier achat… autant de recherches Google qu’il fait *à votre place*.
Impact des AI Overviews et IA mode sur la recherche et la visibilité. Vu par Google…
Plus de contexte, plus de largeur, et surtout plus de sources convoquées qu’avec un seul lien bleu. Et comme l’utilisateur n’a plus besoin de décomposer sa pensée en mots-clés, il cherche plus, et pose des questions plus complexes. Plus de requêtes, plus de slots : plus d’occasions d’apparaître.**
La conclusion que Splitt en tire rejoint le tagline qu’on connaît : good SEO is good GEO. Le socle technique (être crawlable, indexable) reste le prérequis non négociable ; la qualité du contenu fait la différence. Et un effet de bord intéressant qu’il a relevé : à force d’explorer par questions successives, l’utilisateur voit certaines marques revenir encore et encore, et commence à construire une relation avec elles avant même de cliquer. Les opportunités ne sont plus seulement les liens bleus d’hier.

Après, je ne vous cache pas qu’on reconnaît bien le discours officiel de Google. Les AI Overviews et le mode IA seraient très appréciés des utilisateurs. Ils n’auraient aucun impact négatif sur les impressions ou les clics ; au contraire, ils encourageraient les internautes à effectuer davantage de recherches.
Ce qui est moins mis en avant, en revanche, c’est que ces recherches se font de plus en plus directement dans les interfaces IA. De facto, on consulte moins les traditionnels liens bleus. Après, cela reste le discours d’un porte-parole de Google lors d’une conférence Google… difficile de s’attendre à un autre narratif.
Preferred sources : l’arme anti-spam que Google a confiée aux utilisateurs
Splitt a glissé ce sujet presque en passant, mais c’est l’un des mouvements les plus stratégiques de l’année.
Sous la « fonctionnalité de confort » se cache un vrai levier et, à mon sens, une mesure anti-spam qui ne dit pas son nom.
Le mécanisme de Preferred sources
N’importe quel utilisateur peut vous désigner comme source préférée, depuis l’étoile dans Top Stories ou via `google.com/preferences/source`.
Vos contenus remontent plus souvent et plus haut dans Top Stories, Discover, et depuis le 27 mai 2026 dans les AI Overviews et l’AI Mode, avec un badge source préférée visible jusque dans la réponse IA. Splitt l’a formulé clairement : la relation que vous avez déjà avec vos lecteurs est désormais transférée *dans* la recherche, ce qui n’était pas le cas avant. Et vous pouvez la provoquer — un simple bouton « faites de nous votre source préférée » suffit.
Les chiffres sur Preferred sources
Plus de 345 000 sources déjà sélectionnées (environ 4× le niveau de décembre 2025), et surtout : une source préférée est cliquée à peu près deux fois plus qu’un lien équivalent. Dans un monde où le CTR organique s’effondre sous les AI Overviews, ce multiplicateur n’a rien d’anecdotique.

Preferred sources, le nouveau facteur de classement (ranking factor) ?
Ce n’est pas un facteur de ranking universel selon Daniel Waisberg. Accumuler les preferred sources ne fait pas monter votre site pour tout le monde.
C’est un signal personnalisé, il ne joue que pour les utilisateurs qui vous ont déjà choisi. Vous n’élargissez pas votre audience, vous verrouillez celle que vous avez déjà.
Preferred sources, une mesure anti-spam ?
C’est là que c’est malin.
En laissant l’utilisateur curer ses propres sources, Google externalise discrètement une partie de sa lutte anti-spam. Plutôt que d’arbitrer seul, algorithmiquement, quel contenu mérite la confiance, il laisse l’audience faire remonter les sources fiables et, mécaniquement, enterrer le reste : fermes de contenu, sites bardés de pop-ups, tout ce qui est AI slop a vrai dire.
Comment mettre en place Preferred sources ?
Éligibilité pour Preferred sources :
Tout site qui publie du contenu frais (ce n’est plus réservé à la presse), au niveau domaine ou sous-domaine, pas les sous-dossiers. Il faut être correctement indexé, conforme aux guidelines, avec des données structurées propres. Pas de candidature manuelle : c’est algorithmique.
Le deep link à diffuser pour devenir source préférée (Preferred sources) ?
google.com/preferences/source?q=votredomaine.com`, un clic, le domaine est pré-rempli. Google fournit même des boutons officiels en 16 langues.
Où placer le lien source préférée (Preferred sources ) ?
- en fin d’article fort,
- en footer de newsletter,
- dans la bio auteur.
Comment connaître le nombre d’utilisateurs qui vous ont comme source préférée (Preferred sources) ?
Aucun indicateur natif (Waisberg a reconnu en Q&A que l’équipe y réfléchissait). En attendant, un event GA4 sur le clic du CTA, plus le suivi des impressions Top Stories / Discover comme proxy.
Vous l’avez compris, le contenu non-commodity attire le lecteur, le statut de preferred source le fidélise dans les réponses IA. Dans un index où l’IA absorbe tout le générique.
Le tag « Highly Cited » : Google rend la citation visible, et c’est énorme
Dans la même salve d’annonces, Google a sorti l’autre pièce du puzzle, et celle-là est sous-estimée : l’expansion du badge Highly Cited.
Le label n’est pas neuf, il existe depuis 2022 dans Top Stories, mais le 27 mai 2026, Google l’a étendu à bien plus de liens web dans les résultats, et a ajouté une indication quand un article référence lui-même une source Highly Cited. Bref, il sort de sa niche presse pour devenir un signal de confiance à l’échelle du SERP.
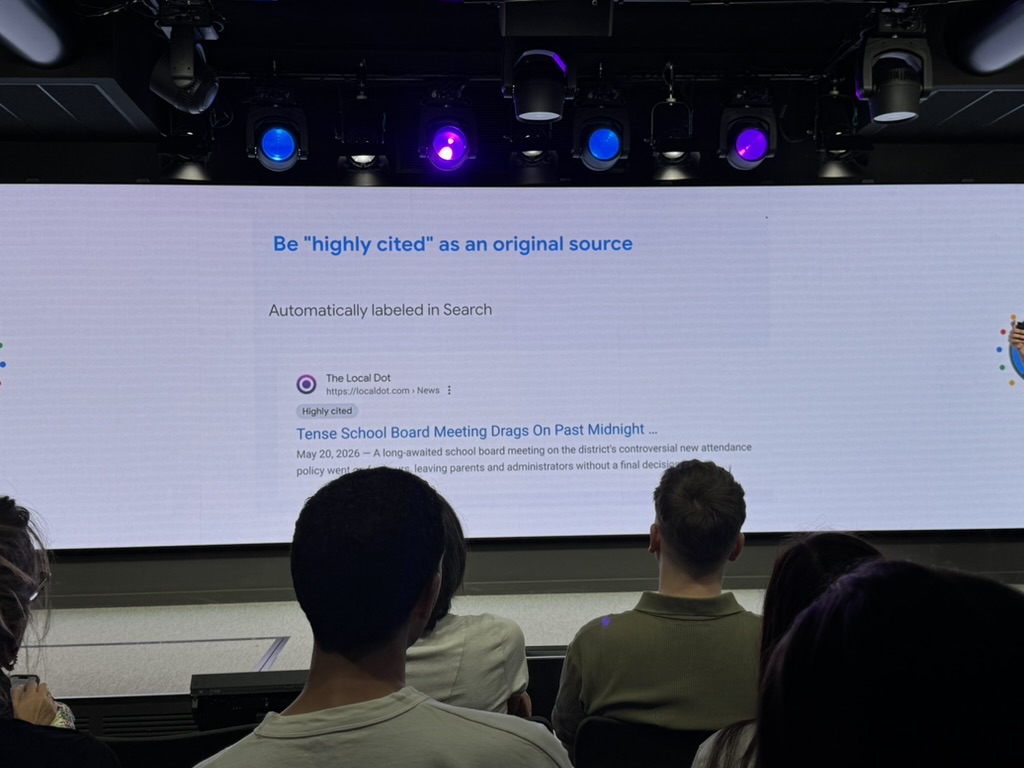
Utilité du tag Highly Cited
Il flague l’article que les autres citent, la source primaire derrière une histoire, celle que tout le monde reprend. Concrètement : vous écrivez l’enquête, les vingt autres sites la paraphrasent, et c’est *vous* qui portez le badge. Pour une fois, le crédit remonte à l’auteur de l’info, pas à ceux qui la recopient.
Comment obtenir le tag Highly Cited ?
Aucune candidature, aucun réglage : c’est algorithmique, basé sur la fréquence à laquelle d’autres éditeurs (surtout des médias, sur du reporting original) vous référencent et vous relient. Autrement dit, c’est le vieux signal des backlinks éditoriaux… rendu visible à l’utilisateur sous forme de badge de crédibilité.
Pourquoi le tag Highly Cited est important ?
Deux raisons selon moi :
- D’abord, c’est l’arme anti copier-coller de Google : à l’heure où l’AI slop recopie et reformule le travail des autres, le label cherche à réacheminer le crédit vers la source originale.
- Ensuite, et c’est le vrai sujet : l’IA déplace le jeu du ranking de page vers l’autorité de source. Dans un moteur à réponses, ce qui compte n’est plus seulement ma page se classe, c’est suis-je la source que tout le monde cite ? Parce que c’est exactement ce que les systèmes IA récompensent quand ils assemblent une réponse. Le badge Highly Cited, c’est cette autorité-là rendue lisible, à la fois pour l’utilisateur et comme signal de l’originalité que les surfaces IA privilégient.
D’après Search Engine Land, l’expansion du badge se fait à travers le SERP et n’est pas propre à l’AI Mode ou aux AI Overviews, ce n’est donc pas (encore) un badge qui s’affiche dans la réponse IA elle-même. Mais la logique, elle, est purement ère-IA, et elle prolonge tout ce qu’on vient de dire : le preferred source mobilise votre audience, le Highly Cited certifie votre autorité auprès de vos pairs. Les deux convergent vers la même idée, devenir la source qu’on cite et qu’on choisit
Pour les SEO et les éditeurs, la to-do est limpide : du reporting original, de la donnée propriétaire, des études, des interviews, du contenu si singulier que les autres sont obligés de vous citer. C’est un peu le non commodity content prise par l’autre bout : non seulement le générique vous fait sortir de l’index, mais l’original vous fait gagner un badge qui vous distingue dedans.
Subscription Linking (Reader Revenue Manager) :
Dernier levier côté éditeurs, et celui-ci vise spécifiquement les sites à abonnement : le Subscription Linking via le Reader Revenue Manager (RRM). Splitt a lâché un chiffre qui a fait lever quelques sourcils dans la salle : +34 % d’engagement pour les utilisateurs qui ramènent leur abonnement dans la recherche.
Le problème que ça règle.
Un paywall crée un angle mort : votre abonné paie déjà, mais depuis un résultat de recherche, il ne sait pas quels articles sont couverts par son abonnement. Il peut donc tomber sur un mur… qu’il a déjà payé pour franchir. Le Subscription Linking permet à ce lecteur de relier son abonnement à son compte Google ; en retour, un panneau Depuis vos abonnements apparaît dans Google Search, Discover et News, mettant en avant le contenu auquel il a droit. Les abonnés passés par « Subscribe with Google » y sont automatiquement intégrés.
Les top keywords de l’AI Mode : explain, find, identify, summarize

Une slide que j’ai shootée vaut tout un audit d’intention : les mots-clés qui dominent les recherches en AI Mode. Le palmarès ? Explain, Find, Information, Identify, Summarize. Regardez-les bien : ce ne sont pas des requêtes navigationnelles ni des mots-clés produits. Ce sont des verbes cognitifs. L’utilisateur ne tape plus « meilleur CRM 2026 », il demande à l’IA d’expliquer, d’identifier, de résumer, de trouver l’information à sa place.
Conséquence directe pour votre contenu : il doit être explicable, résumable, identifiable. Une page qui répond proprement à « explique-moi X », « identifie les différences entre Y et Z », « résume les options » a bien plus de chances d’être mobilisée dans une réponse IA qu’un mur de texte optimisé à l’ancienne. Structurez pour la synthèse : définitions nettes, comparatifs explicites, réponses directes en tête de section. L’IA cherche des briques qu’elle peut citer, pas des paragraphes qu’elle doit décortiquer.
Mesurer sa visibilité à l’ère du GEO : Trends + Search Console
La mesure était l’autre fil de la journée, et une slide résumait l’approche : croiser deux sources de données complémentaires. D’un côté, Google Trends avec Terms, Topics, Geo, Interest : la demande, ce que les gens cherchent, où, avec quelle dynamique. De l’autre, la Search Console avec Queries, Pages, Geo, Impressions, Clicks, Position : votre performance réelle, ce que vous captez vraiment.

Discover, le terrain de jeu français
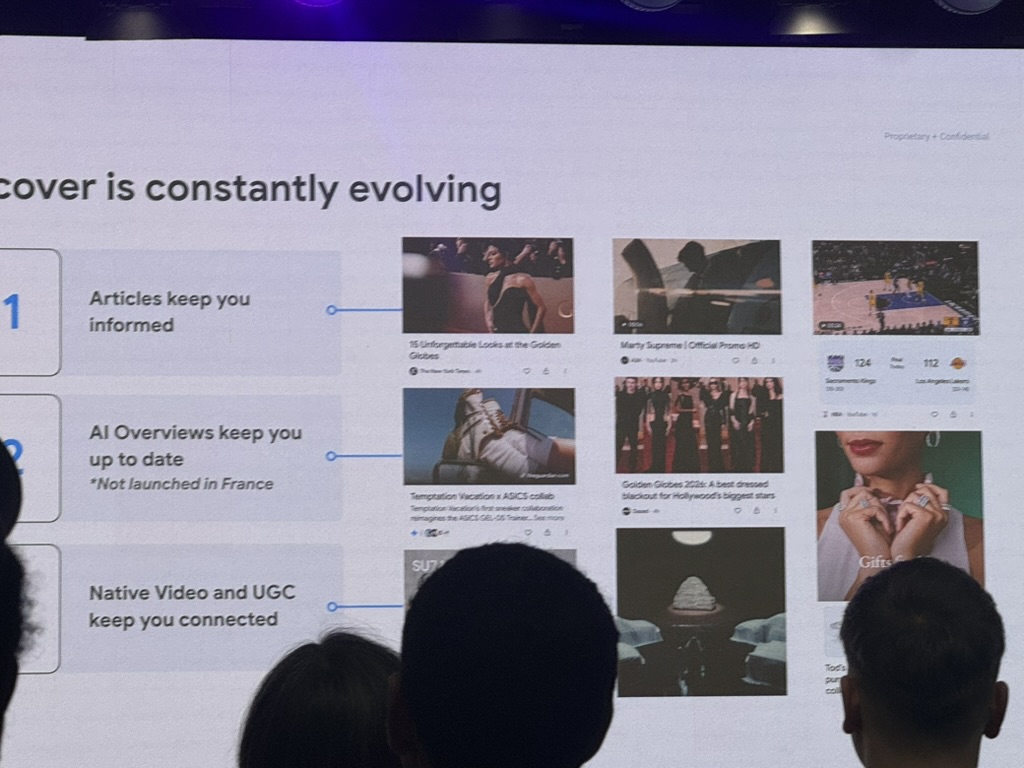
Pendant que les AI Overviews se font attendre chez nous, Discover reste la surface IA-adjacente la plus puissante accessible aux éditeurs français. Trois slides l’ont illustré.
1. Discover ne cesse d’évoluer.
Le slide « Discover is constantly evolving » pose trois rôles : les articles informent, les AI Overviews tiennent à jour — avec, là encore, l’astérisque qui pique : « Not launched in France » —, et la vidéo native + l’UGC maintiennent le lien. Traduction : Discover devient multi-format. Si vous misez tout sur l’article texte, vous jouez sur un tiers du terrain seulement ; la vidéo native et les contenus de créateurs y prennent une place croissante.
2. Trust & Safety veille au grain.
Shivani Gupta (Trust & Safety) a montré la mécanique de fond : un cycle Partner Compliance ↔ Proactive/Reactive Content Reviews. Derrière la promesse éditoriale, il y a une couche d’application des règles — conformité des partenaires et revues de contenu, proactives comme réactives. C’est le bras armé anti-AI-slop de Discover : votre éligibilité dépend autant du respect des policies que de la qualité perçue. Un manquement, et vous sortez du feed.

3. Le Core Update privilégie l’expertise.
La slide la plus parlante pour les SEO : « Core Update: why we surface expertise ». Trois colonnes
- Purpose : garantir un reporting crédible, fiable, expert ;
- Process : Discover mesure l’autorité de l’éditeur pour distinguer le reporting pertinent et exact du contenu low-quality ;
- Benefit : livrer du contenu en profondeur, original et opportun. Retenez la formule exacte : Discover measures publisher authority. C’est l’E-E-A-T dit sans détour, et c’est le fil rouge de toute la journée, celui qui relie le Highly Cited, le commodity content et les preferred sources : l’autorité de la source est devenue le produit.

Le Q&A Google Search Central Paris : ce que Google a (et n’a pas) voulu répondre






Le Q&A s’est tenu sur des questions soumises à l’avance via un formulaire et Google a posé d’emblée sa règle du jeu, savoureuse : toute question commençant par « quand… » a été écartée. Si on avait quelque chose à annoncer, on l’aurait annoncé. Voilà pour le calendrier. Pour le reste, les réponses qui valent le détour.
IA dans le workflow éditorial : jusqu’où aller ?
Google se moque de comment le contenu est produit ; il regarde ce qui est publié. Beaucoup d’IA pour produire de l’excellent contenu : parfait. Un peu d’IA plus du scripting pour pondre 1 000 pages par jour : passif. Rappel utile, le low-effort n’a pas attendu l’IA : un humain produit très bien du contenu vide.
Et si je bascule vers du low-cost pour tenir le rythme ?
La réponse de Mueller fait froid dans le dos et recoupe la fluidité de l’index : les signaux de qualité au niveau du site mettent du temps à se mettre à jour. Si vous dégradez votre contenu, une quality update finira par étiqueter votre site « globalement peu qualitatif » et là, la chute (search et Discover) peut prendre plusieurs mois, parfois plus d’un an à se résorber. Ce n’est pas un 404 qu’on corrige : aucun Googler ne « répare » une réputation à la main. Mieux vaut éviter que guérir.

Pourquoi seulement 16 mois d’historique dans la Search Console ?
Pour permettre les comparaisons année sur année par trimestre (15 mois + 1 pour analyser). Au-delà, c’est un arbitrage avec la vitesse de l’interface (10 ans de données = des rapports qui mettent des minutes à charger). Seuls ~2 % des utilisateurs en demandent plus.
Sinon, exportez (API, BigQuery, ou des outils tiers qui déversent la GSC dans un Sheet) et utilisez la fonction feedback de la Search Console, ils la lisent et agissent dessus.
Pourquoi mes chiffres GSC ne tombent jamais juste quand je filtre ?
Le coupable : l’échantillonnage. Chaque filtre applique un sampling ; filtrez deux fois et vous samplez sur du samplé → le graphe affiche 20 000 clics, le tableau en somme 10 000. La parade unique : export BigQuery, bien plus complet que l’UI et que l’API (qui tape de la donnée déjà compressée). Conservable jusqu’à ~100 mois — ça coûte, prévenez la compta.
Contenu sponsorisé / publi-rédactionnel : quel marquage ?
Aucun label spécifique côté search. L’essentiel : signaler les liens sponsorisés avec l’attribut normal (rel="sponsored"). Vous pouvez bloquer l’indexation, ce n’est pas obligatoire. Google News et Discover peuvent différer.
Une API pour pousser mon contenu directement à Google (MCP & co) ?
La réponse remet les pendules à l’heure : crawler n’est pas le goulot d’étranglement, le vrai problème de Google, c’est de reconnaître le bon contenu. S’il sait le repérer, le crawl classique suffit à le faire remonter. L’Indexing API existe, mais réservée au contenu très volatil (news, vidéo, offres d’emploi). Une API « upload » généraliste ? Peut-être un jour, pas la priorité.
Identifier les requêtes B2B à faible volume mais à forte valeur ?
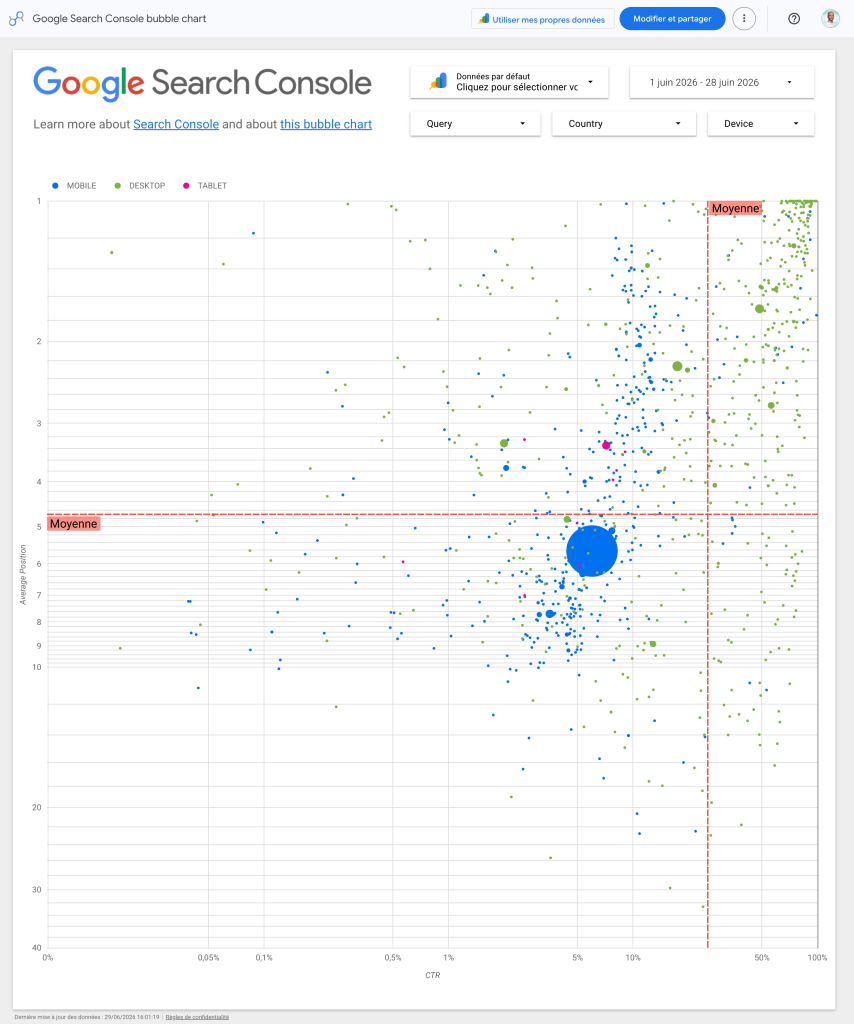
La pépite actionnable de la session ? un template Google à l’appui developers.google.com/search/docs/monitor-debug/bubble-chart-analysis.
Chaque bulle = un mot-clé, la taille = les clics, la couleur = le device.
La zone à travailler : position moyenne mais CTR élevé — ceux qui les voient cliquent, donc gagner une ou deux positions y produit un effet disproportionné. C’est là que va votre effort éditorial, pas sur les mots-clés déjà en tête.
Plusieurs autres questions : configuration de paywall (toutes équivalentes côté search), stats de preferred sources, accès agentique à sécuriser en priorité, markdown/llms.txt ont reçu des réponses déjà détaillées plus haut. Google a été remarquablement constant d’un bout à l’autre : qualité du contenu, fondamentaux techniques, patience sur l’IA.
Google Search Central Live Paris – 26 juin 2026 – résumé
Google n’a pas lâché de date pour l’arrivée des AI overviews et IA mode en France, mais on a eu un petit avant gout sur ce qui nous attends : le commerce agentique n’est plus de la prospective, c’est le chantier en cours. WebMCP côté site, UCP côté plateforme, AP2 côté paiement : la pile est posée, les partenaires sont là, et Mueller vous demande, à sa manière prudente mais répétée, de ne pas attendre.
La bonne nouvelle, c’est que le ticket d’entrée n’a rien d’ésotérique : un crawl propre, des feeds cohérents, des données structurées solides. Du tech SEO de fond. La même hygiène qu’avant, appliquée à un nouvel acheteur, qui cette fois n’est pas humain.
Good GEO is good SEO. Et bientôt, good agentic commerce, aussi.
- Google Search Central Live Paris 2026 : Google mise sur l’agentique
- AI Overviews et IA Mode en France : Google confirme l’arrivée (MAJ 24 juin 2026)
- VivaTech 2026 vu par un SEO/GEO : qui était là, qui manquait, et la montée du « bad AI »
- Google Search Central – Paris – Juin 2026
- Checklist GEO de Google : comment optimiser son site pour les agents IA
Laisser un commentaire
Vous devez vous connecter pour publier un commentaire.