Classic SEO (TF-IDF, keywords) is not suitable for RAG systems.
LLMS do not deal with lexical chains but Vector representations.
The main criterion is the Semantic similarity between a query and content.
Tools like Screaming Frog Seo Spider already make it possible to estimate this similarity on the text side.
For my part, I developed scripts to go further (chunking, scoring per passage, etc.).
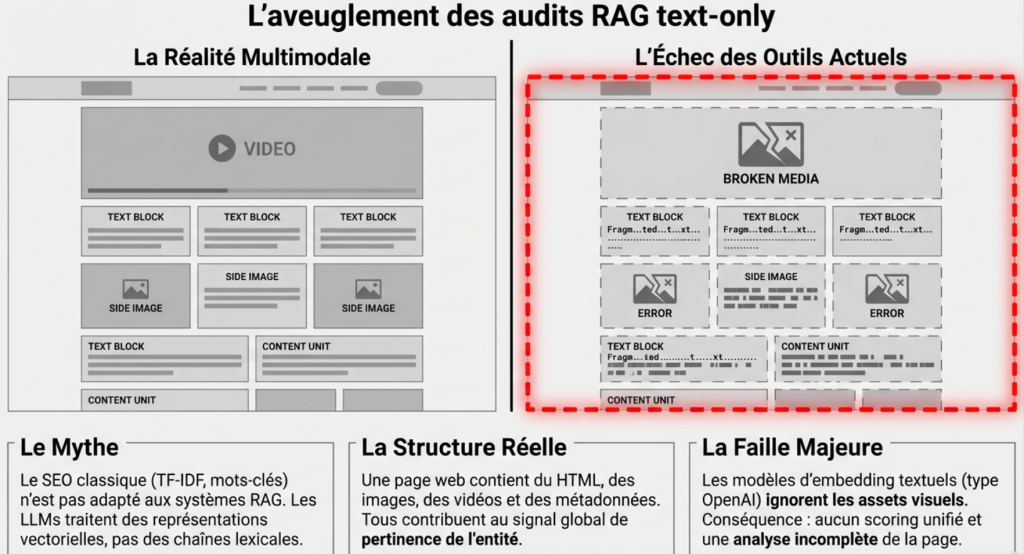
But a web page, nowadays, is multimodal:
We find:
- Text (HTML)
- imagery
- videos
- metadata
- sometimes audio
These elements all contribute to the global signal used during the retrieval.
The majority of current audits use models text-only (like the series text-embedding DopenAI). This method is incomplete.
Traditional tools before Gemini Embedding 2 do not:
- The vectorization of all these assets
- No unified scoring
- No visibility on the contribution of each element
Result:
- Identification of weak chunks
- Image impact measurement
- Prioritization of optimizations based on scores
Why Gemini-Embdding-2?
With the publication of Google Gemini-Embedd-2, this point is resolved.
What does the model actually do:
- Text + image vectorization in the same space
- Homogeneous similarity calculation
- Scoring by Asset
- Aggregation in overall score
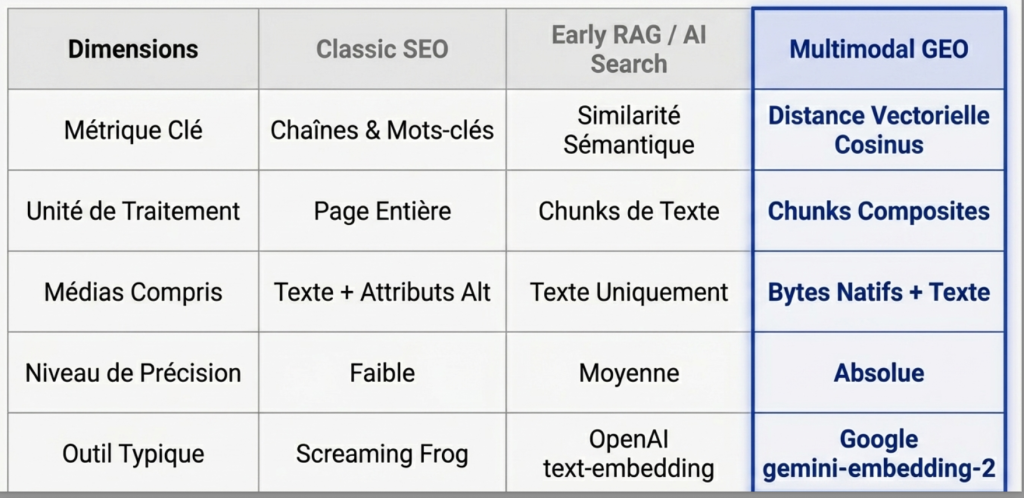
lstructural advantage of gemini-embedding-2-preview lies in its ability to natively process composite objects. The script is not satisfied withAnalyze the alternative text dan image; It directly transmits bytes (bytes) of theImage via class types.part.from_bytes to model dEmbedding to project them in the same vector space as the text query.
Multimodal Geo Audit with Gemini-Embedding-2
RAG ENGINES do not ingest a web page as a block. They ‘chunk’ it (cut it into passages) to maximize the relevance in their context window.
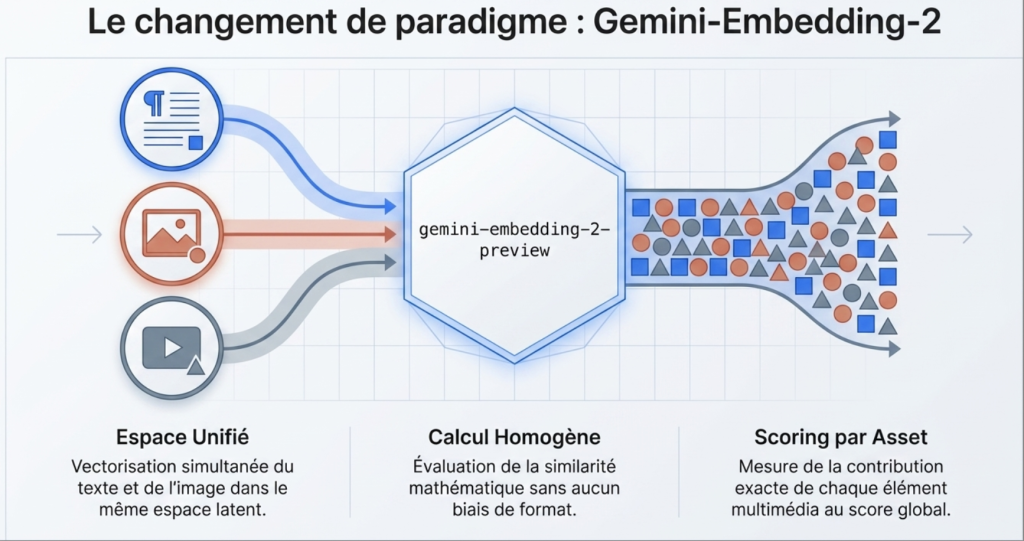
The Multimodal GEO auditor reproduces this exact behavior:
Extraction of the Central entity: If no query is provided, the tool uses an LLM (gemini-2.5-flash) in ‘Quality Rater’ mode to read the DOM and extract the Pure Search Intent (Core Search Intent). Dan Petrovic (Dejan Ai) has widely demonstrated that the Modern optimization targets features, not character strings.
Contextual chunk: HTML is cleaned from noise (header, footer, nav). The tags <p> are concatenated with their parent title (<H2> or <h3>).

Native multimodal evaluation: Cis the strength of Gemini-Embedd-2. Instead of reading only theattribute alt Done image, the script downloads theimage and sends its bytes (bytes) direct to the model. lImage is vectorized and compared to the text query in the same multidimensional space.
Mathematical calculation: relevance is more than an opinion, it’s a cosine distance between the chunk vector (text or image) and the query vector.
How to use the GEO Multimodal auditor
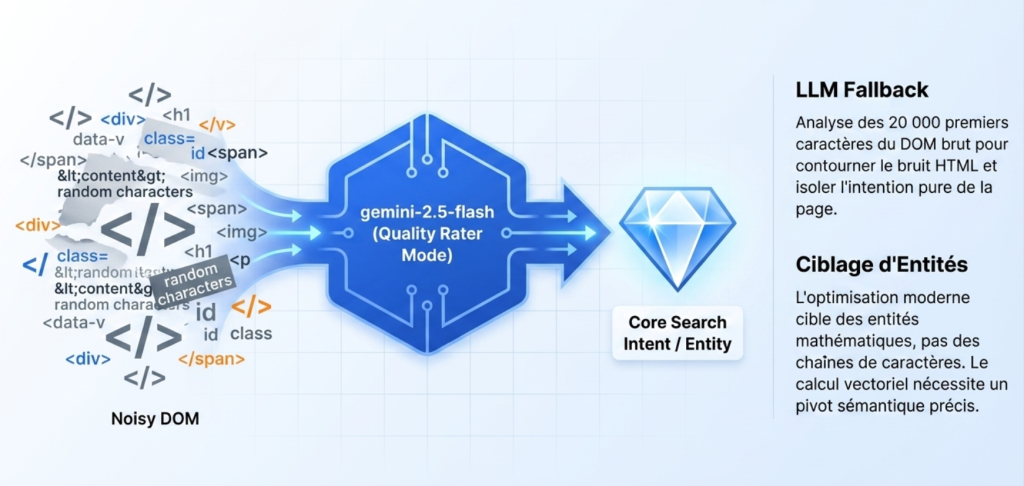
Extraction of the entity and Intention (LLM Fallback)
If the audit is launched without a strict target query, it is detected by the model, the script uses gemini-2.5-flash with a prompt like a Quality assessor (Search Quality Rater) on the first 20,000 characters of the raw DOM.
The goal is to isolate the ‘Core Search Intent’. The LLM therefore identifies the Entity processed by the page before the vector calculation.
Chunking and passage indexing
Martin Splitt (Google) as well as the director of Perplexity have repeatedly confirmed that the indexing and Relevance assessment separate at the passage level, not the global page. The script uses beautifulsoup To clean the code (removal of <Nav>, <footer>, <Aside>, <script>).
The logic of chunk Preserve the context:
- The tags
<p>are extracted and concatenated with their parent subtitle (<h1>,<H2>,<h3>). - For tags
<img>, Lsource URL is extracted. The file is downloaded, converted if necessary (to JPEG for compatibility), and associated with the direct surrounding paragraph to provide a position context.
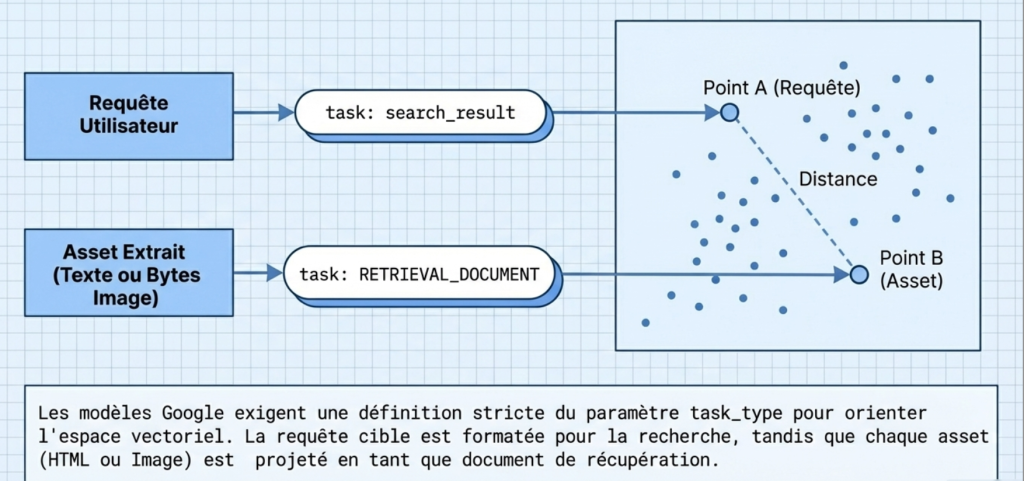
Vector projection
Google templates require strict setting of the setting TASK_TYPE To calibrate the latent space.
- The target query vector is generated with the directive
Task: Search Result. - Each asset Extract (text, binary image, PDF link) is vectorized with
Task: retrieval_document.
Cosine distance calculation and weighting matrix
semantic proximity is calculated via the function cosine From the Scipy bookstore: score = float(1 - cosine(query_vec, vec)). A score of 1.0 indicates an absolute vector match.
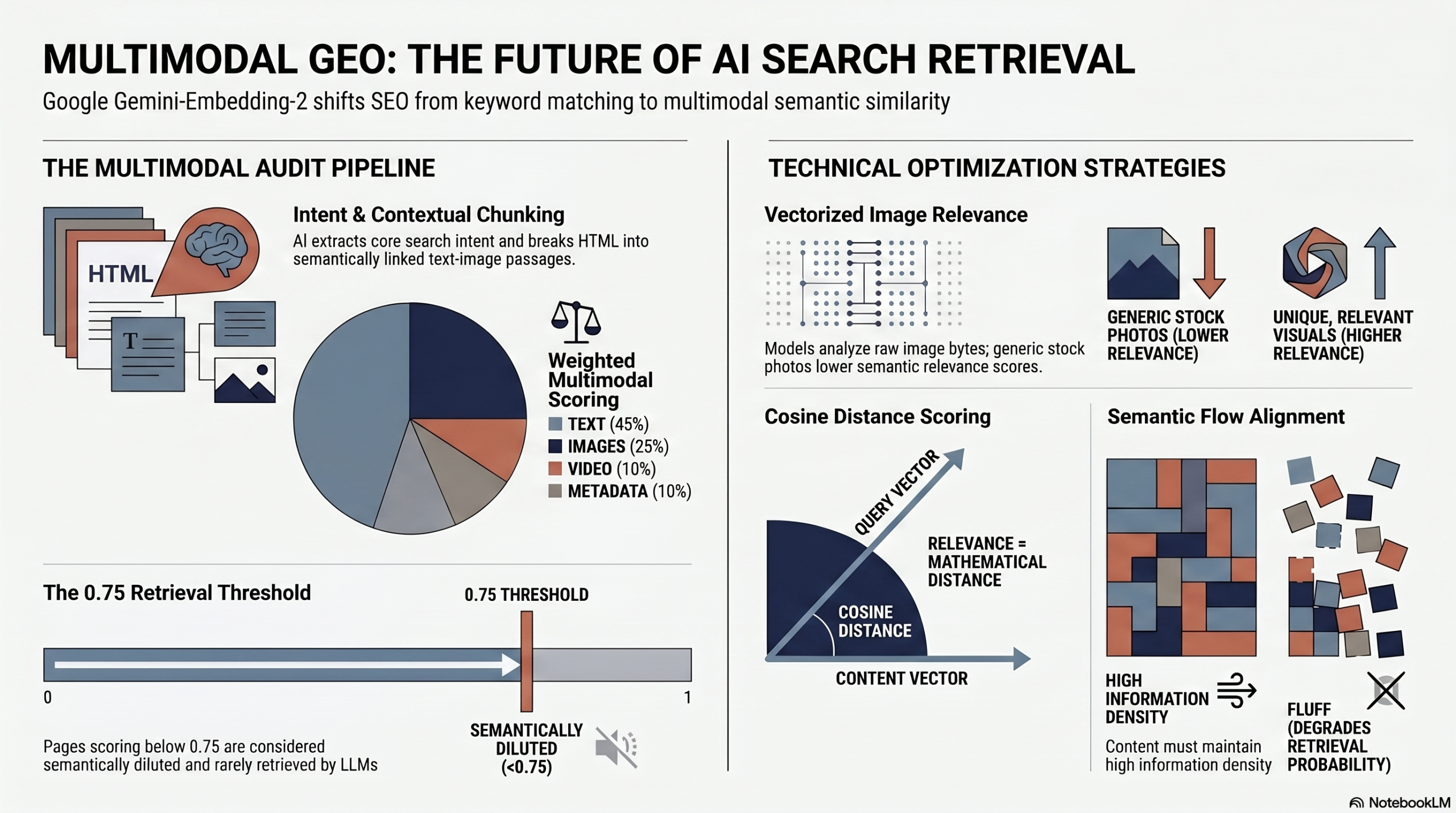
To evaluate the page, jApplies a weighting matrix:
- HTML (text): 45%
- Image (bytes): 25%
- D metadataImage (if download failed): 10%
- Video: 10%
- Audio / PDF: 5%
A RAG viability threshold is set at 0.75.
The ‘gap’ is calculated for each asset (0.75 - Score). the priority of Intervention Sobtains by multiplying this gap by the weight of the Element (Weight * Gap).
Example DA multimodal GEO audit with Gemini Embedding 2
I have tested with the following URL: https://aioseo.fr/en/bing-ai-performance-how-to-exploit-the-data-for-ranker-on-chatgpt-copilot-and-other-llm/
Data extracted
- Resolved query: Bing AI Data for LLM Ranking
- Audited assets: 35 (text blocks and media)
- Overall Geo Score: 0.6585 (i.e. 65.85/100)
Multimodal Geo Performance Analysis
The overall score is 0.658. below the 0.75 minimum cosine similarity requested.
the data generated in the reports (in particular the Semantic Flow and the priority matrix) reveal the penalty mechanics:
- Semantic dilution: Text passages (HTML) have a strong variance. Some paragraphs skeep away from the entity Bing AI Data. Lily Ray and Aleyda Solis regularly underline the importance of the density of the information (gain information) for theE-E-A-T. An LLM sanctions peripheral content (Fluff). If a chunk drops to 0.50, it degrades the overall score by 45%.
- Multimodal mismatch: Generic or decorative images generate very low cosine scores. The template literally vectorizes pixels. If Limage does not contain visual data correlated to the Intention (Bing dashboards, ranking diagrams), its vector strongly diverges from the query.
Graph decortication
Here is how to read and exploit the 6 graphics generated during this audit.
The multimodal global score
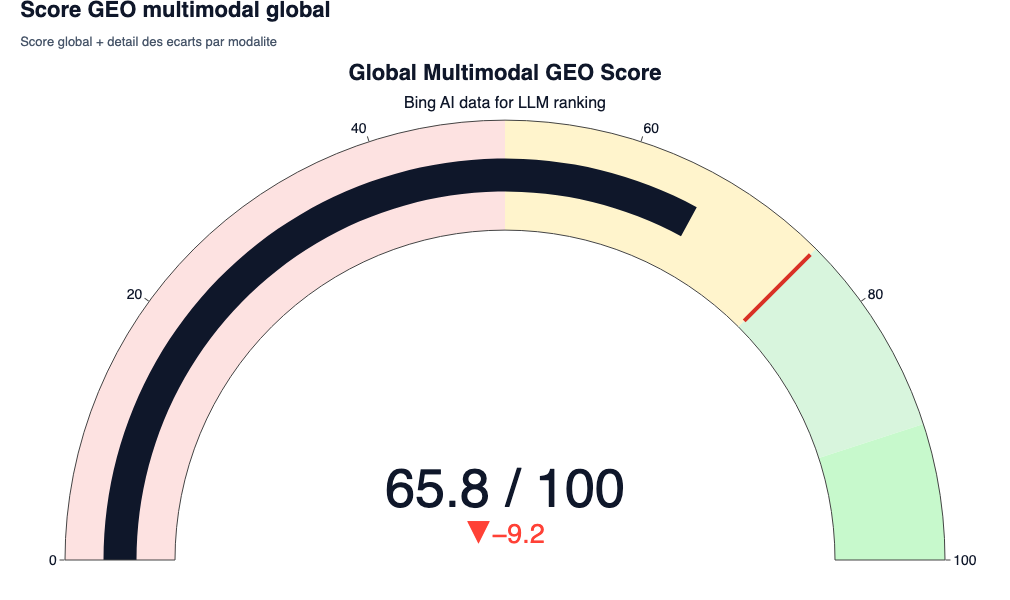
The result: 0.6585 / 1.0 (i.e. 65.85%)
- what You have to understand: This score is a weighted average (HTML 45%, 25% images, etc.) of the cosine similarities of all page elements. To be systematically extracted by a RAG system, the empirical target is at 0.75.
- SEO/GEO interest: A score of 0.65 indicates that the document is relevant but diluted. If an LLM should choose between your page and a competing page scoring at 0.80 to formulate its AI Overview, it will choose the most dense and closest vector. Your page will not cross the threshold of retrieval.
Multimodal footprint
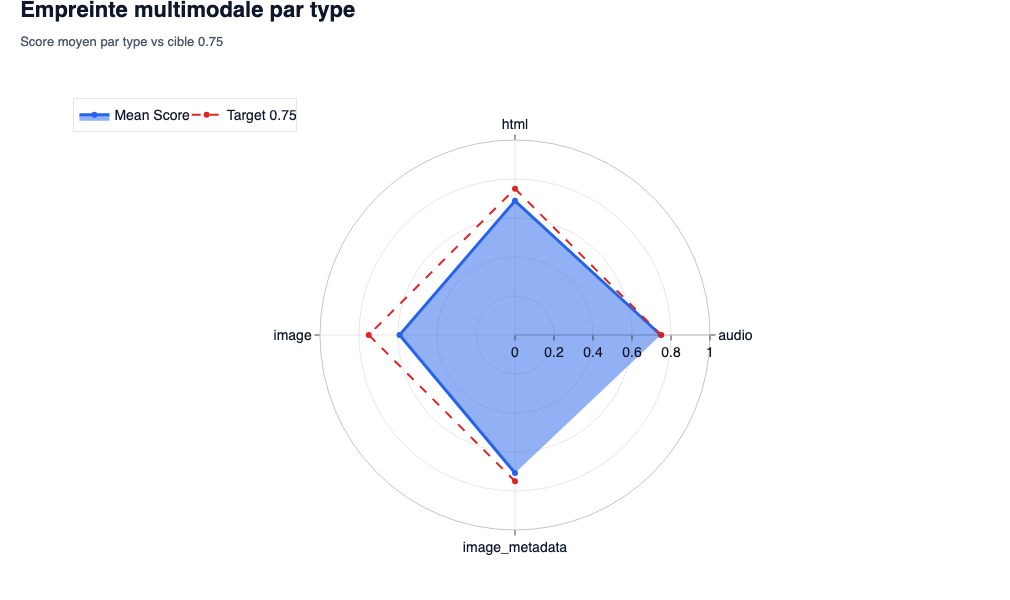
- what the We observe: These graphs compare the average of each format (text, image, video) with the critical red line of the threshold of 0.75.
- SEO/GEO interest: They are used to diagnose the failure by format. In Geo, we often forget the images. If your text scores at 0.80 but your images score at 0.30, your page is penalized. With
Gemini-Embedd-2, a photo of generic bank illustration Images has no vector correlation with lentity Bing AI Data. The model sees pixels that mean nothing from a technical point of view. Result: the ‘image’ mode collapses and pulls the note down.
The semantic flow of passages
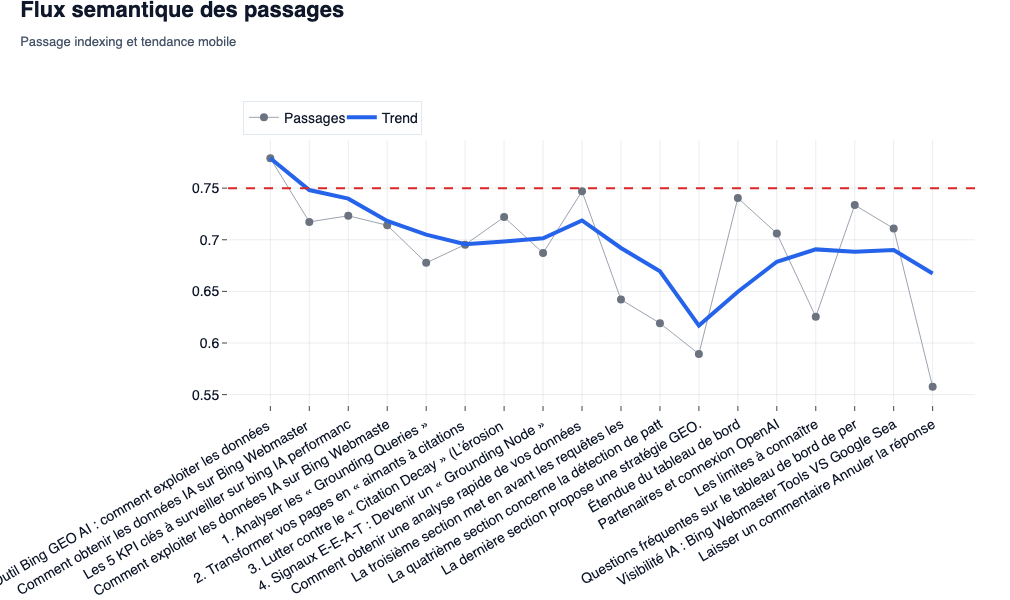
- what theWe observe: a curve that follows the score of each paragraph (
<p>) in his order dAppearance on the page, with a trend line (moving average). - SEO/GEO interest: Cis themost powerful diagnostic tool for theGain information. as pointed out Lily Ray and Aleyda Solis Regarding the E-E-A-T criteria, the density dinformation is queen. If the curve plunges into some sections (for example, an overly long introduction or an off-topic H2), this means that these chunksssemantically move away from the target query. For LLMS, this ‘fluff’ is toxic: it dilutes the relevance of your document in theVector space.
Semantic relevance distribution
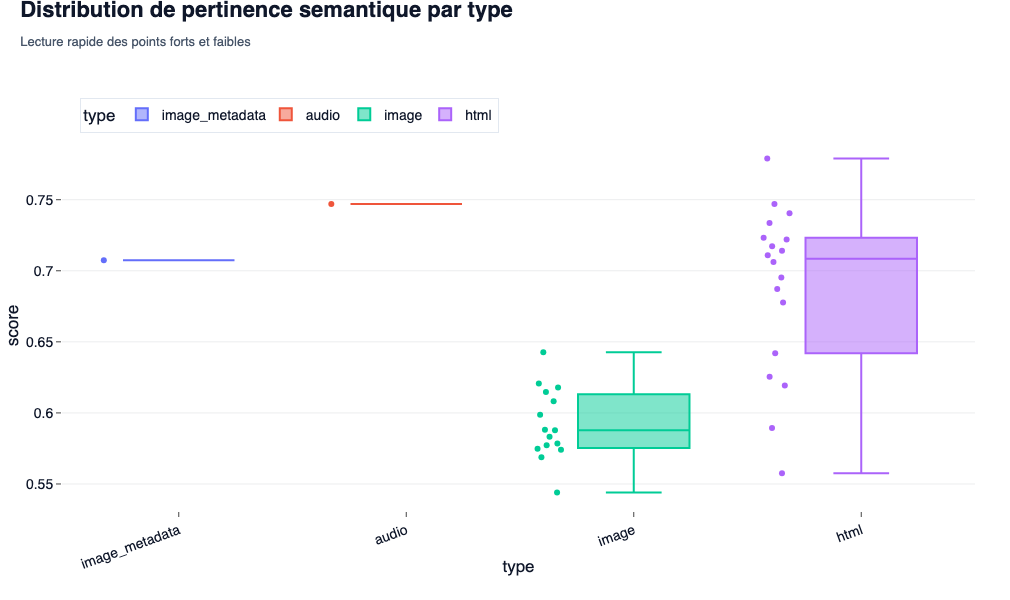
- what theWe observe: the scattering (volatility) of scores within dThe same category (HTML vs images).
- SEO/GEO interest: This indicates the consistency of your content. A very stretched boxplot on HTML shows a heterogeneous page: some passages are dSurgical precision,others are pure filling. In GEO, the regularity (a short boxplot above 0.75) ensures that nwhatever chunk Extracted by the engine will be ultra-relevant to power its response.
The prioritization matrix
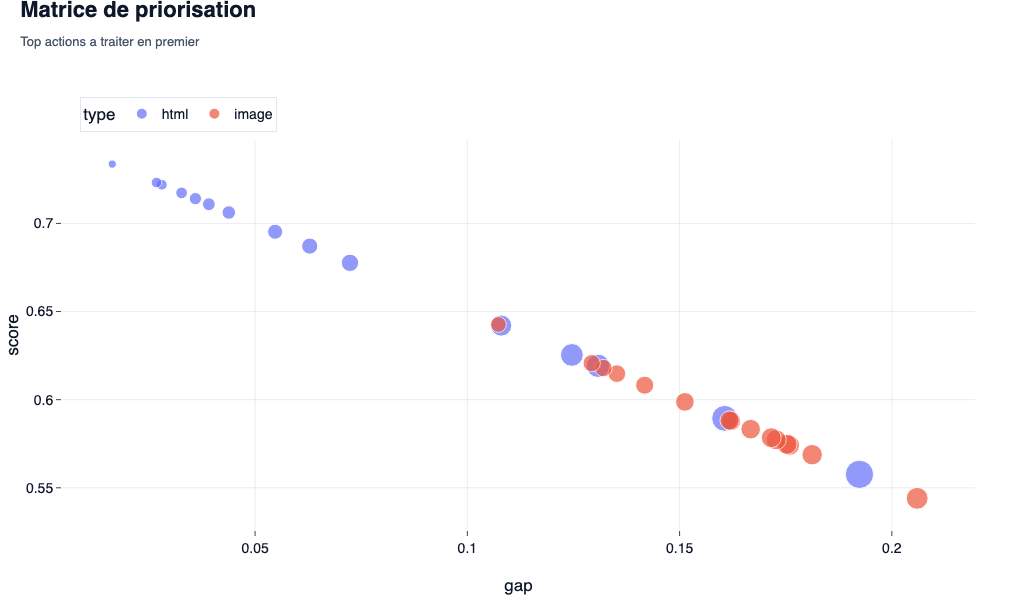
- what theWe observe: a cross between the gap of relevance (the distance that separates theelement of the target score of 0.75) and the weight of Lelement in the page. The bigger and higher the bubble, the moreemergency is great.
- lSEO/GEO interest: Cis your roadmap Mathematical editorial. duringA classic audit, we tell you ‘improving the content’. Here, the matrix (and theexport CSV associated) dictates to you exactly what h2 or what picture must be deleted or rewritten in priority to leverage on the overall score. We no longer modifyBlind.
Examples of recommendations to optimize multimodal GEO
Based on these results, we can suggest:
- Pruning Weak Chunks: View the file
action_backlog.csvgenerated by the script. Sort by columnpriority. any block<p>whose cosine score is less than 0.70 must be ruthlessly removed or densified with a technical vocabulary strictly related to scraping, APIs orLLM architecture. - Image Replacement by Visual Data: lEvaluation by
bytesRequires informative visuals. Replace images dillustration by captures ofAnnotated screen of Bing Webmaster Tools reports. The Gemini model will align the vector of these new images with that of the query, mechanically increasing the score of the ‘Image’ category (which weighs 25% of the final score). - HN/P structural alignment: Mark Williams-Cook validated that semantic search systems depend ona deterministic markup. each text located under a
<H2>must respond immediately to the promise of this title. the concatenation made during the chunk (Heading: text) Requires this semantic proximity to generate a powerful vector.
Leave a Reply
You must be logged in to post a comment.