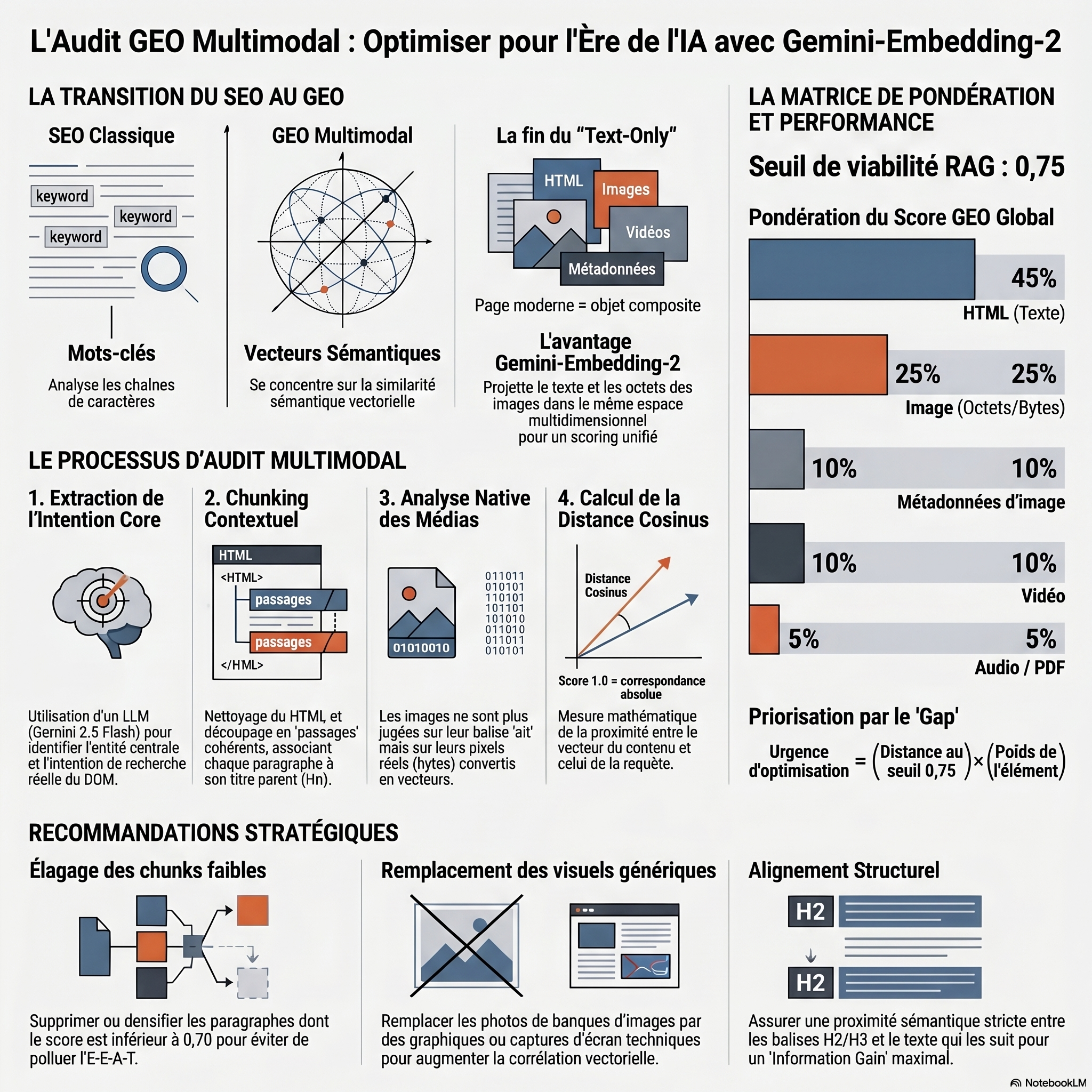
Le SEO classique (TF-IDF, mots-clés) n’est pas adapté aux systèmes RAG.
Les LLMs ne traitent pas des chaînes lexicales mais des représentations vectorielles.
Le critère principal est la similarité sémantique entre une requête et un contenu.
Des outils comme Screaming Frog SEO Spider permettent déjà d’estimer cette similarité côté texte.
De mon côté, j’ai développé des scripts pour aller plus loin (chunking, scoring par passage, etc.).
Mais une page web, de nos jours, est multimodale :
On trouve :
- texte (HTML)
- images
- vidéos
- métadonnées
- parfois audio
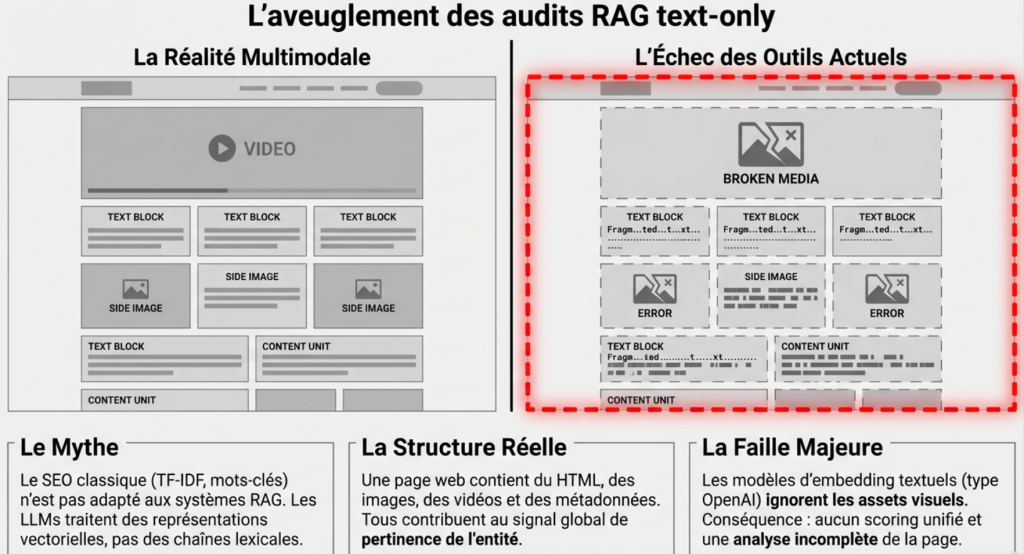
Ces éléments contribuent tous au signal global utilisé lors du retrieval.
La majorité des audits actuels utilisent des modèles text-only (comme la série text-embedding d’OpenAI). Cette méthode est incomplète.
Les outils traditionnels avant gemini embedding 2 ne font pas :
- la vectorisation de tous ces assets
- pas de scoring unifié
- pas de visibilité sur la contribution de chaque élément
Résultat :
- identification des chunks faibles
- mesure de l’impact des images
- priorisation des optimisations basée sur des scores
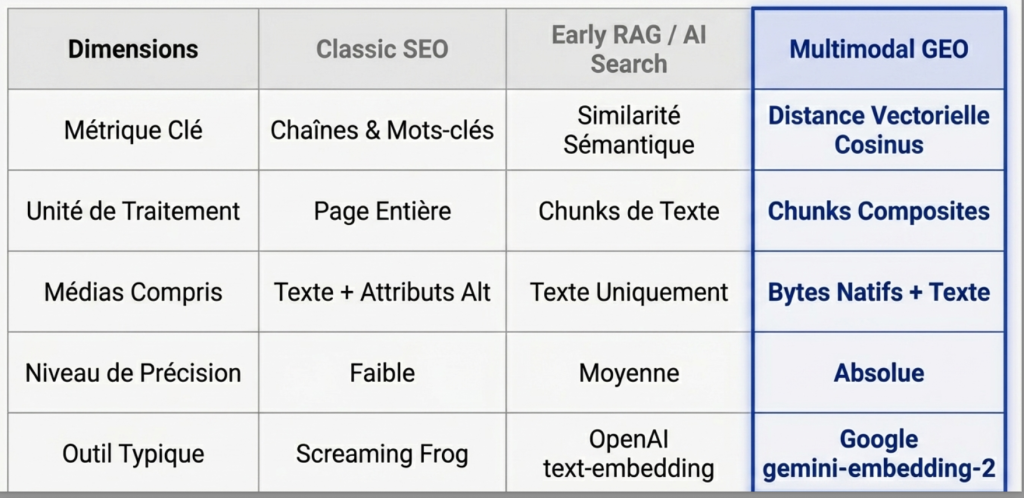
Pourquoi Gemini-Embedding-2 ?
Avec la publication de Google gemini-embedding-2, ce point est résolu.
Ce que ça permet concrètement le model :
- vectorisation texte + image dans le même espace
- calcul de similarité homogène
- scoring par asset
- agrégation en score global
L’avantage structurel de gemini-embedding-2-preview réside dans sa capacité à traiter nativement des objets composites. Le script ne se contente pas d’analyser le texte alternatif d’une image ; il transmet directement les octets (bytes) de l’image via la classe types.Part.from_bytes au modèle d’embedding pour les projeter dans le même espace vectoriel que la requête textuelle.
Audit GEO multimodal avec Gemini-Embedding-2
Les moteurs RAG n’ingèrent pas une page web d’un bloc. Ils la « chunquent » (la découpent en passages) pour maximiser la pertinence dans leur fenêtre de contexte.
L’audit GEO Multimodal reproduit ce comportement exact :
Extraction de l’Entité Centrale : Si aucune requête n’est fournie, l’outil utilise un LLM (gemini-2.5-flash) en mode « Quality Rater » pour lire le DOM et en extraire l’intention de recherche pure (Core Search Intent). Dan Petrovic (Dejan AI) a largement démontré que l’optimisation moderne cible des entités, pas des chaînes de caractères.
Chunking Contextuel : Le HTML est nettoyé du bruit (header, footer, nav). Les balises <p> sont concaténées avec leur intertitre parent (<h2> ou <h3>).

Évaluation Multimodale Native : C’est la force de gemini-embedding-2. Au lieu de lire uniquement l’attribut alt d’une image, le script télécharge l’image et envoie ses octets (bytes) directs au modèle. L’image est vectorisée et comparée à la requête textuelle dans le même espace multidimensionnel.
Calcul Mathématique : La pertinence n’est plus une opinion, c’est une distance cosinus entre le vecteur du chunk (texte ou image) et le vecteur de la requête.
Fonctionnement de l’auditeur GEO multimodal
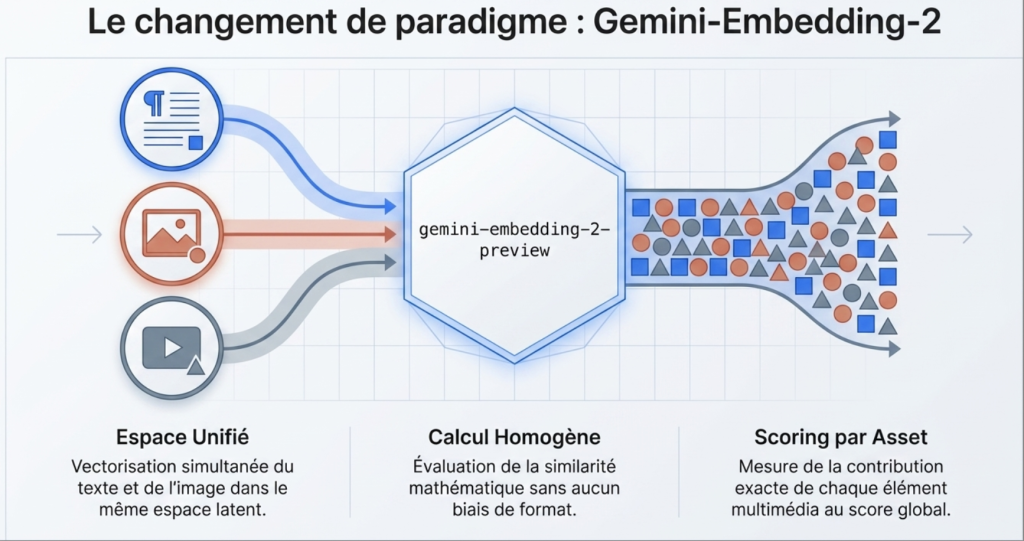
Extraction de l’Entité et de l’Intention (LLM Fallback)
Si l’audit est lancé sans requête cible stricte(chose que je fais pour voir la thématique détectée par le model), le script utilise gemini-2.5-flash avec un prompt d’évaluateur de qualité (Search Quality Rater) sur les 20 000 premiers caractères du DOM brut.
Le but est d’isoler le « Core Search Intent ». Le LLM identifie donc l’entité traitée par la page avant le calcul vectoriel.
Chunking et Passage Indexing
Martin Splitt (Google) ainsi que le directeur de Perplexity ont confirmé à de multiples reprises que l’indexation et l’évaluation de la pertinence s’opèrent au niveau du passage, et non de la page globale. Le script utilise BeautifulSoup pour nettoyer le code (suppression de <nav>, <footer>, <aside>, <script>).
La logique de chunking préserve le contexte :
- Les balises
<p>sont extraites et concaténées avec leur intertitre parent (<h1>,<h2>,<h3>). - Pour les balises
<img>, l’URL source est extraite. Le fichier est téléchargé, converti si nécessaire (vers JPEG pour la compatibilité), et associé au paragraphe environnant direct pour fournir un contexte de position.
Projection Vectorielle
Les modèles Google exigent une définition stricte du paramètre task_type pour calibrer l’espace latent.
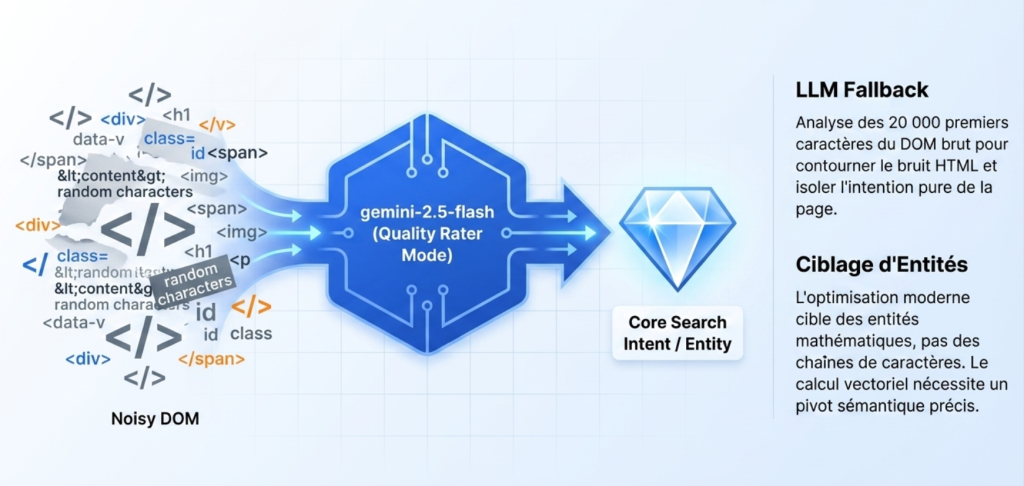
- Le vecteur de la requête cible est généré avec la directive
task: search result. - Chaque asset extrait (texte, image binaire, lien PDF) est vectorisé avec
task: RETRIEVAL_DOCUMENT.
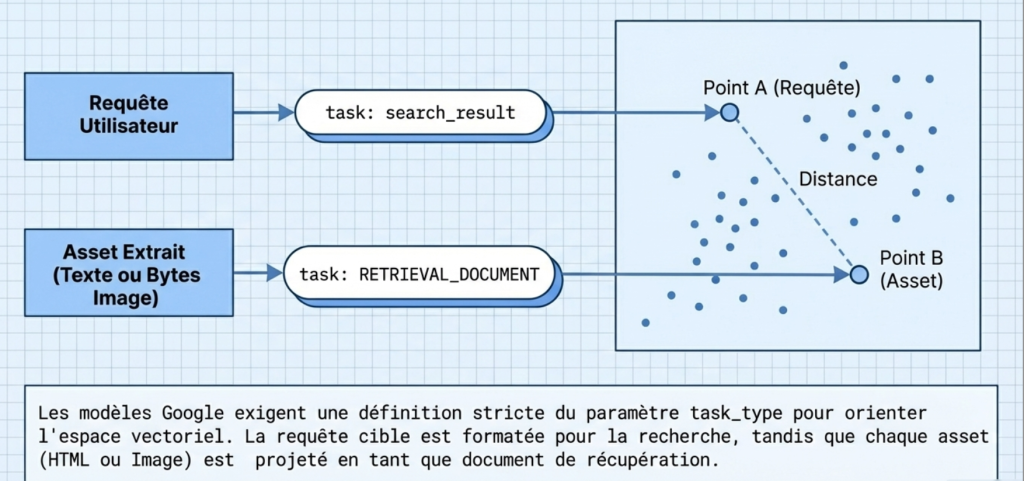
Calcul de Distance Cosinus et Matrice de Pondération
La proximité sémantique est calculée via la fonction cosine de la librairie SciPy : Score = float(1 - cosine(query_vec, vec)). Un score de 1.0 indique une correspondance vectorielle absolue.
Pour évaluer la page, j’applique une matrice de pondération :
- HTML (Texte) : 45%
- Image (Bytes) : 25%
- Métadonnées d’image (si échec du téléchargement) : 10%
- Vidéo : 10%
- Audio / PDF : 5%
Un seuil de viabilité RAG est fixé à 0.75.
Le « Gap » est calculé pour chaque asset (0.75 - score). La priorité d’intervention s’obtient en multipliant ce Gap par le poids de l’élément (weight * gap).
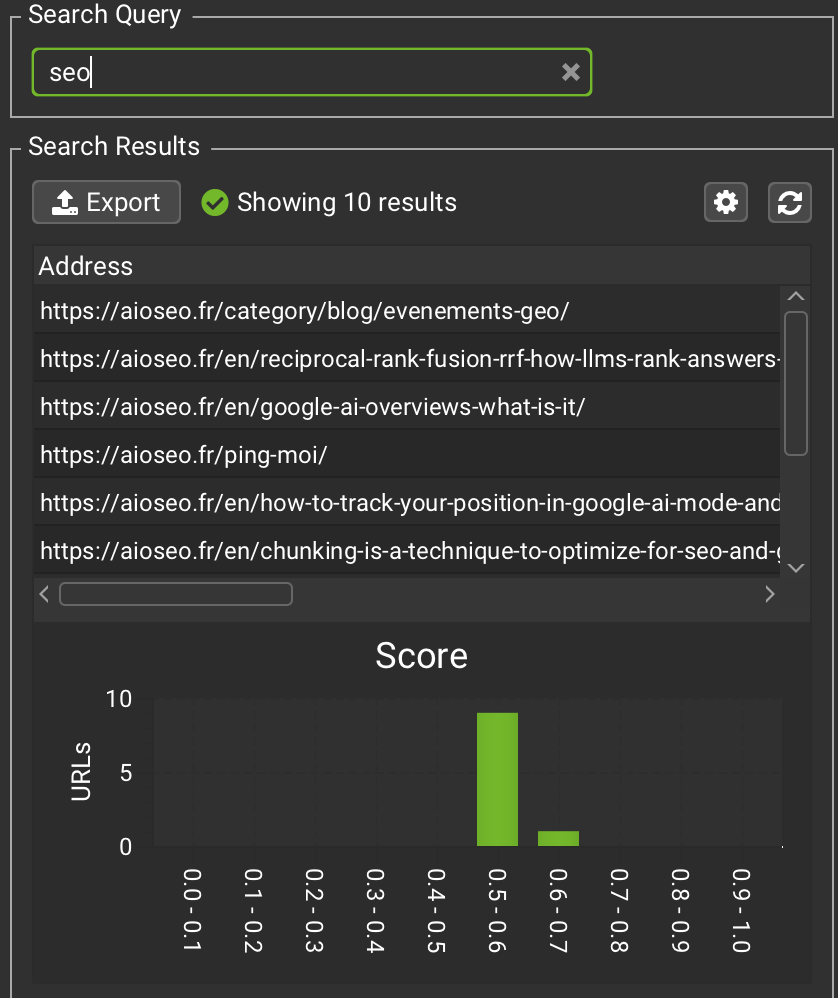
Exemple d’un audit GEO multimodal avec Gemini Embedding 2
J’ai testé avec l’URL suivante : https://aioseo.fr/bing-ai-performance-comment-exploiter-les-donnees-pour-ranker-sur-chatgpt-copilot-et-autres-llm/
Données extraites
- Requête résolue : Bing AI data for LLM ranking
- Assets audités : 35 (blocs de texte et médias)
- Score GEO Global : 0.6585 (soit 65.85/100)
Analyse de la performance GEO multimodale
Le score global est de 0.658. en dessous des 0.75 de similarité cosinus minimale demandée.
Les données générées dans les rapports (notamment le Semantic Flow et la matrice de priorité) révèlent la mécanique de pénalisation :
- Dilution Sémantique : Les passages textuels (HTML) présentent une forte variance. Certains paragraphes s’éloignent de l’entité Bing AI data. Lily Ray et Aleyda Solis soulignent régulièrement l’importance de la densité de l’information (Information Gain) pour l’E-E-A-T. Un LLM sanctionne le contenu périphérique (fluff). Si un chunkdescend à 0.50, il dégrade le score global de 45%.
- Inadéquation Multimodale : Les images génériques ou décoratives génèrent des scores cosinus très bas. Le modèle vectorise littéralement les pixels. Si l’image ne contient pas de données visuelles corrélées à l’intention (tableaux de bord Bing, schémas de ranking), son vecteur diverge fortement de la requête.
Décortication des Graphes
Voici comment lire et exploiter les 6 graphiques générés lors de cet audit.
Le Score Global Multimodal
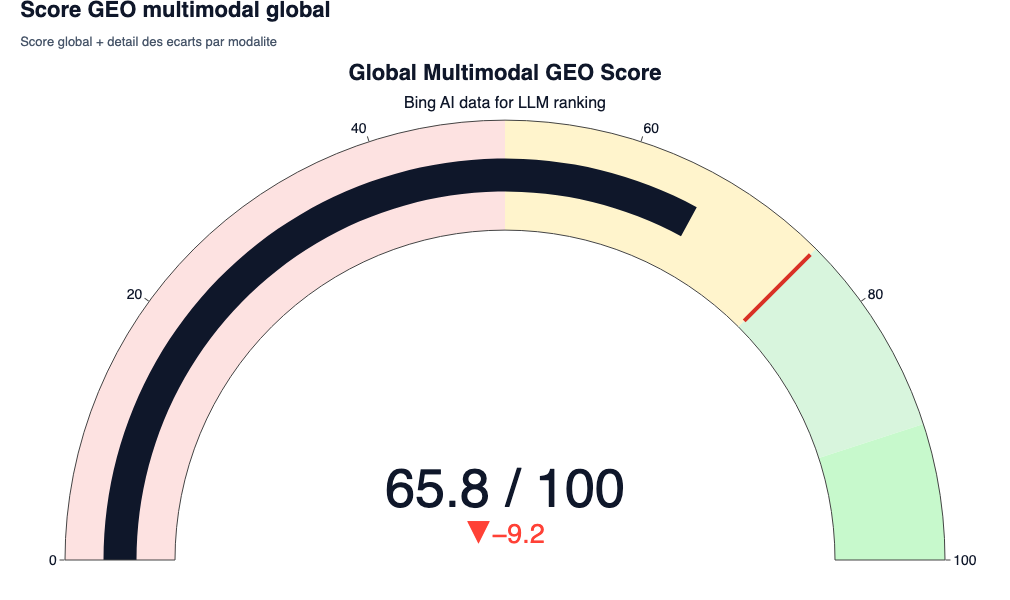
Le résultat : 0.6585 / 1.0 (soit 65.85%)
- Ce qu’il faut comprendre : Ce score est une moyenne pondérée (HTML 45%, Images 25%, etc.) des similarités cosinus de tous les éléments de la page. Pour être systématiquement extrait par un système RAG, la cible empirique se situe à 0.75.
- L’intérêt SEO/GEO : Un score de 0.65 indique que le document est pertinent mais dilué. Si un LLM doit choisir entre votre page et une page concurrente scorant à 0.80 pour formuler son AI Overview, il choisira le vecteur le plus dense et le plus proche. Votre page ne passera pas le seuil de retrieval.
Empreinte Multimodale
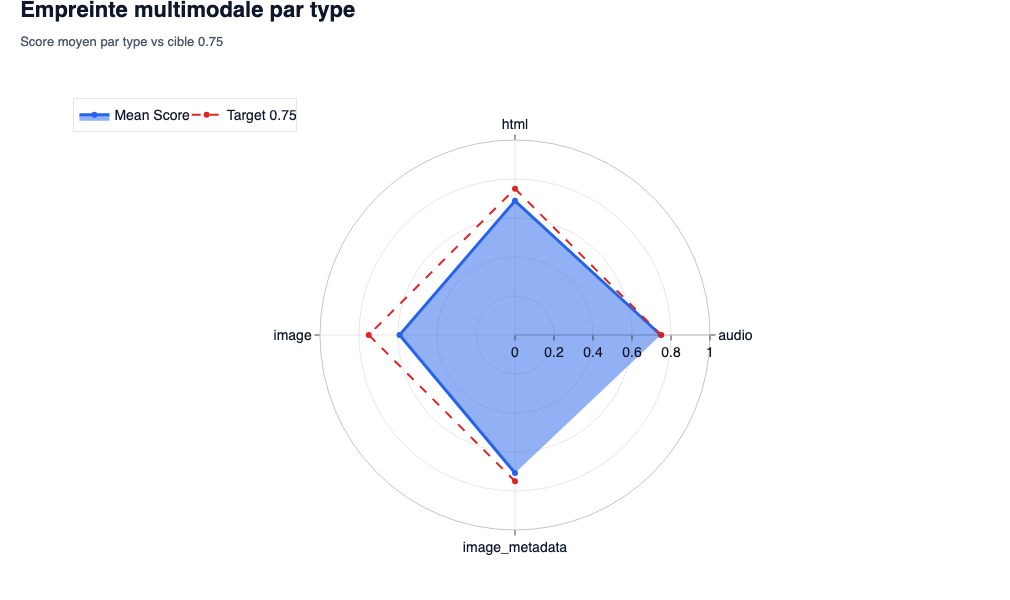
- Ce que l’on observe : Ces graphiques confrontent la moyenne de chaque format (Texte, Image, Vidéo) à la ligne rouge critique du seuil de 0.75.
- L’intérêt SEO/GEO : Ils permettent de diagnostiquer la défaillance par format. En GEO, on oublie souvent les images. Si votre texte score à 0.80 mais que vos images scorent à 0.30, votre page est pénalisée. Avec
gemini-embedding-2, une photo d’illustration générique de banque d’images n’a aucune corrélation vectorielle avec l’entité Bing AI data. Le modèle voit des pixels qui ne veulent rien dire d’un point de vue technique. Résultat : la modalité « Image » s’effondre et tire la note vers le bas.
Le Flux Sémantique des Passages
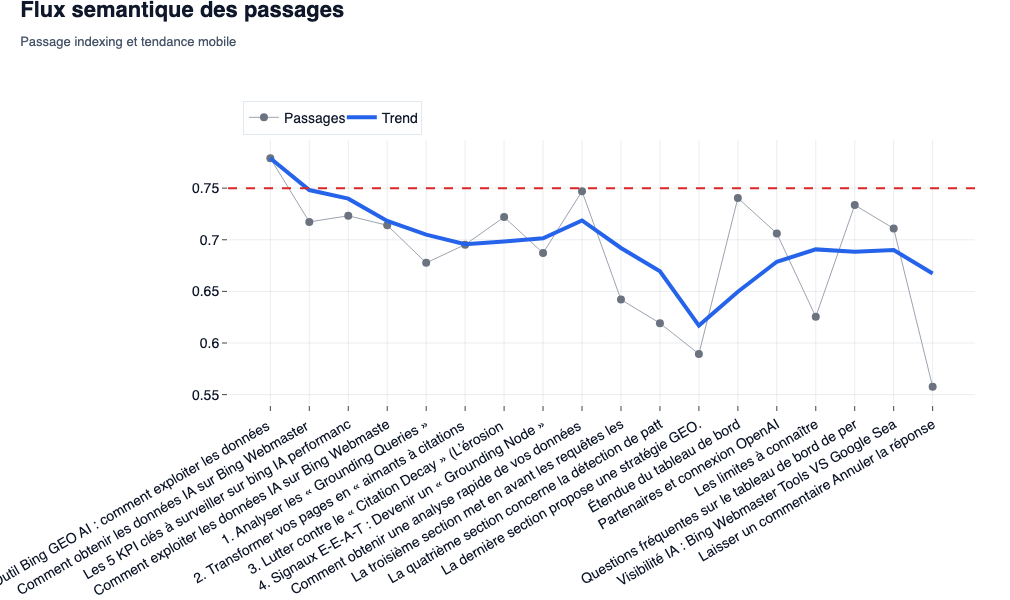
- Ce que l’on observe : Une courbe qui suit le score de chaque paragraphe (
<p>) dans son ordre d’apparition sur la page, avec une ligne de tendance (moyenne mobile). - L’intérêt SEO/GEO : C’est l’outil de diagnostic le plus puissant pour l’Information Gain. Comme le soulignent Lily Ray et Aleyda Solis concernant les critères E-E-A-T, la densité d’information est reine. Si la courbe plonge sur certaines sections (par exemple, une introduction trop longue ou un H2 hors-sujet), cela signifie que ces chunkss’éloignent sémantiquement de la requête cible. Pour les LLMs, ce « fluff » est toxique : il dilue la pertinence de votre document dans l’espace vectoriel.
Distribution de Pertinence Sémantique
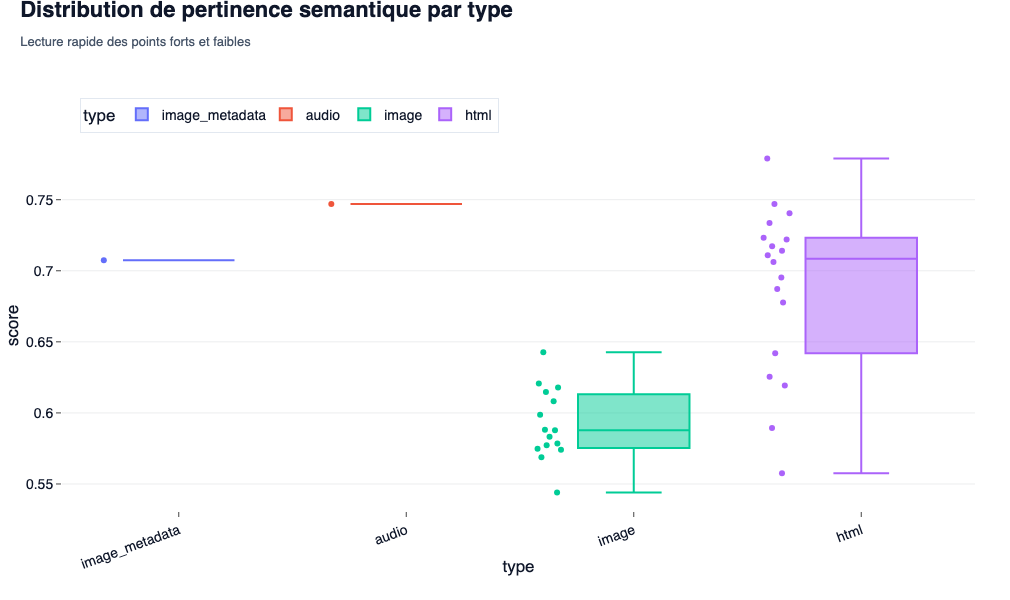
- Ce que l’on observe : La dispersion (volatilité) des scores au sein d’une même catégorie (HTML vs Images).
- L’intérêt SEO/GEO : Cela indique la régularité de votre contenu. Un boxplot très étiré sur le HTML montre une page hétérogène : certains passages sont d’une précision chirurgicale, d’autres sont du remplissage pur. En GEO, la régularité (un boxplot court et situé au-dessus de 0.75) garantit que n’importe quel chunk extrait par le moteur sera ultra-pertinent pour alimenter sa réponse.
La Matrice de Priorisation
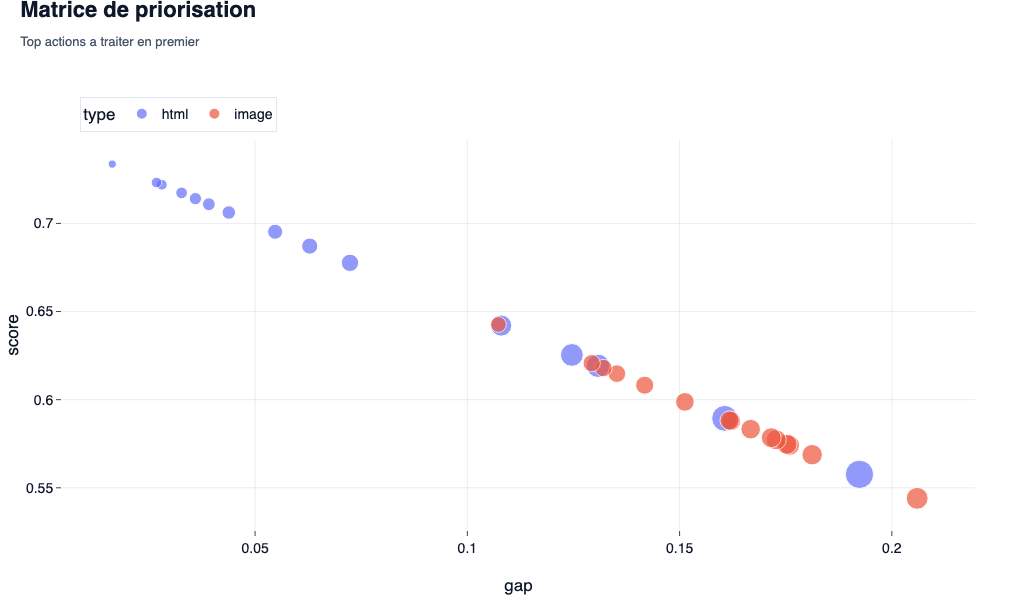
- Ce que l’on observe : Un croisement entre le Gap de pertinence (la distance qui sépare l’élément du score cible de 0.75) et le poids de l’élément dans la page. Plus la bulle est grosse et haute, plus l’urgence est grande.
- L’intérêt SEO/GEO : C’est votre roadmap éditoriale mathématique. Lors d’un audit classique, on vous dit « améliorez le contenu ». Ici, la matrice (et l’export CSV associé) vous dicte exactement quel H2 ou quelle image doit être supprimé ou réécrit en priorité pour faire levier sur le score global. On ne modifie plus à l’aveugle.
Exemples de recommandations pour optimiser le GEO multimodal
Sur la base de ces résultats, on peut proposer :
- Élagage des Chunks Faibles : Consultez le fichier
action_backlog.csvgénéré par le script. Triez par la colonnepriority. Tout bloc<p>dont le score cosinus est inférieur à 0.70 doit être impitoyablement supprimé ou densifié avec un vocabulaire technique strictement lié au scraping, aux APIs ou à l’architecture LLM. - Remplacement Image par Donnée Visuelle : L’évaluation par
bytesexige des visuels informatifs. Remplacez les images d’illustration par des captures d’écran annotées des rapports Bing Webmaster Tools. Le modèle Gemini alignera le vecteur de ces nouvelles images sur celui de la requête, augmentant mécaniquement le score de la catégorie « Image » (qui pèse 25% de la note finale). - Alignement Structurel Hn/P : Mark Williams-Cook a validé que les systèmes de recherche sémantique dépendent d’un balisage déterministe. Chaque texte situé sous un
<h2>doit répondre immédiatement à la promesse de ce titre. La concaténation faite lors du chunking (Heading: text) nécessite cette proximité sémantique pour générer un vecteur performant.
Continuez votre lecture
- Profound vs Semrush AI Visibility Toolkit : lequel suit vraiment votre visibilité IA ?
- ZipTie.dev vs Authoritas : quel outil GEO choisir en 2026 ?
- GEO SEO : Microsoft Clarity et Bing Webmaster Tools, le seul écosystème qui documente vraiment votre visibilité IA
- Google Search Central Live Paris 2026 recap : Google mise sur l’agentique
- AI Overviews et IA Mode en France : Google confirme l’arrivée (MAJ 24 juin 2026)
Laisser un commentaire
Vous devez vous connecter pour publier un commentaire.