mars 4, 2026
J’ai récemment parlé des outils qui promettent de mesurer la visibilité sur Google AI Mode, AI Overviews et les LLM.J’y expliquais pourquoi je ne voyais pas d’urgence à m’y abonner, et pourquoi j’attends plutôt des données IA natives dans Search Console, surtout en France, où ces fonctionnalités ne sont pas encore actives.
Une étude récente montre des écarts marqués entre certaines données API utilisées par ces outils et les réponses réellement affichées.
C’est là que ça devient intéressant.
Les IA détestent le bullshit
Première trouvaille (un peu anecdotique, mais parlante) : les IA détestent le bullshit.
Les longues intros, l’excès de détails, le jargon inutile, tout ça, il faut oublier.
Ça marchait à l’époque du Helpful Content Update de Google, mais même Google a lâché l’affaire. Aujourd’hui, il faut aller droit au but.
Entrons donc dans le vif du sujet !
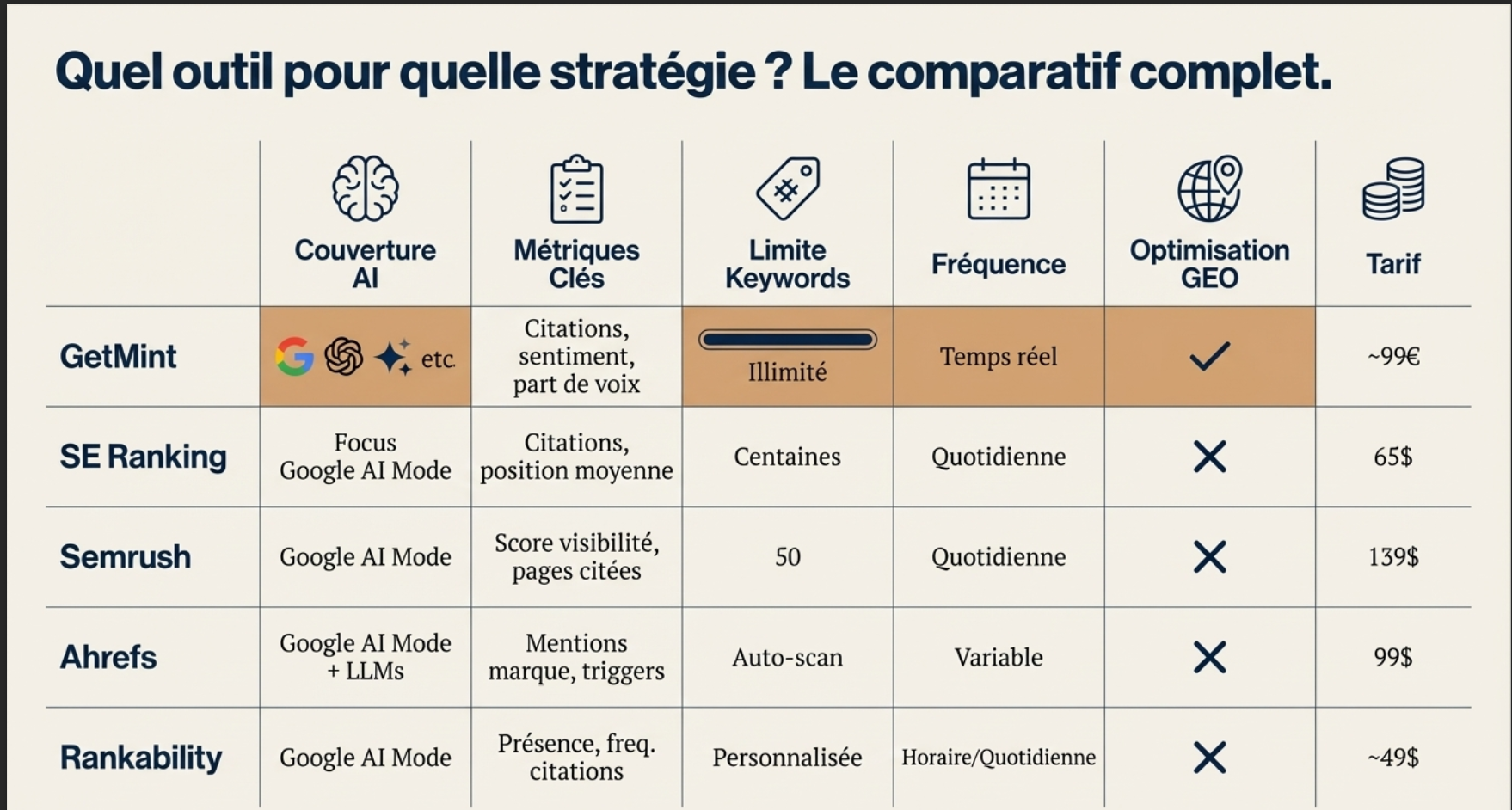
Réponses générées par l’IA par scraping vs résultats API. Quelles différences ?
L’étude mentionnée plus haut a été réalisée par Surfer Blog, que je ne connaissais pas auparavant. Les résultats sont toutefois très intéressants.
Voici les principales trouvailles sous forme de tableau :
| Aspect | Résultats API | Résultats réels (scraping) | Commentaire |
|---|---|---|---|
| Longueur des réponses | ~406 mots en moyenne | ~743 mots en moyenne | Les réponses API sont souvent plus courtes et moins détaillées que ce que voit réellement l’utilisateur |
| Déclenchement du Web Search | ~23 % des réponses ne déclenchent pas de recherche, surtout si <100 mots | Toujours déclenché | Les réponses scrapées contiennent plus de sources et plus diversifiées |
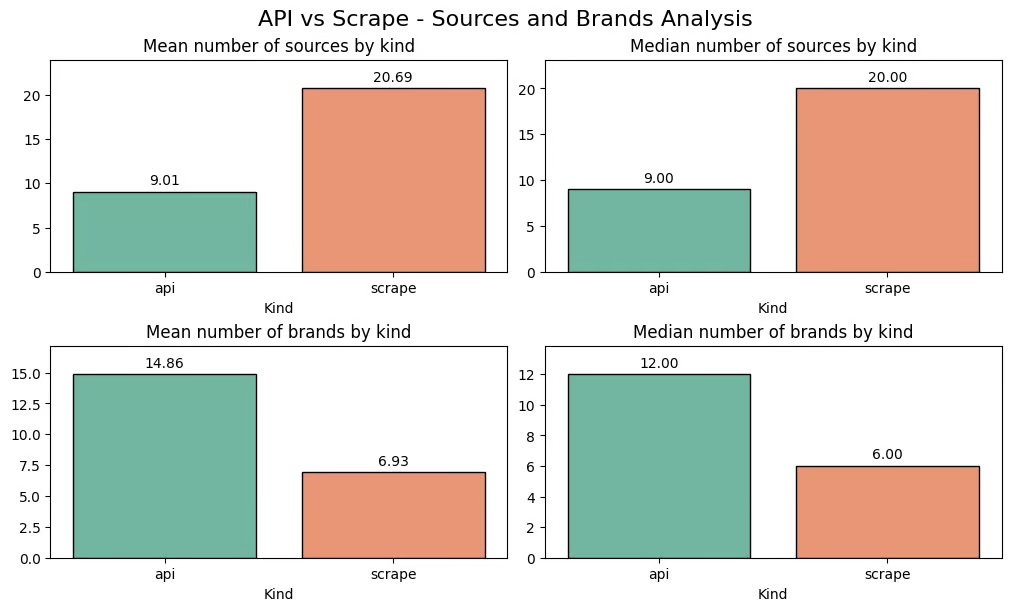
| Sources citées | Aucune source dans ~25 % des cas ; moyenne 7 sources | Toujours présentes ; moyenne 16 sources | Les réponses réelles fournissent presque deux fois plus de sources |
| Détection de marques | 8 % des réponses ne détectent aucune marque ; moyenne 12 marques lorsqu’il y en a | Toujours détectées ; moyenne 9 marques | L’API détecte en moyenne plus de marques par réponse, mais en rate certaines |
| Recoupement API vs scraping | — | — | Seules 24 % des marques et 4 % des sources se recoupent entre API et scraping |
| Résumé global | Données plus structurées, plus courtes, parfois incomplètes | Données plus longues, complètes, avec la logique de l’interface et toutes les sources | Pour construire des apps : API → idéal ; pour surveiller l’expérience réelle : scraping → indispensable |
Chatgpt :résultats API vs résultats réels
Surfer a comparé environ 2 000 requêtes : la même question posée à ChatGPT (et Perplexity) via API vs. les réponses réellement affichées à un utilisateur (scrap). Et les différences sont substantiellement importantes.
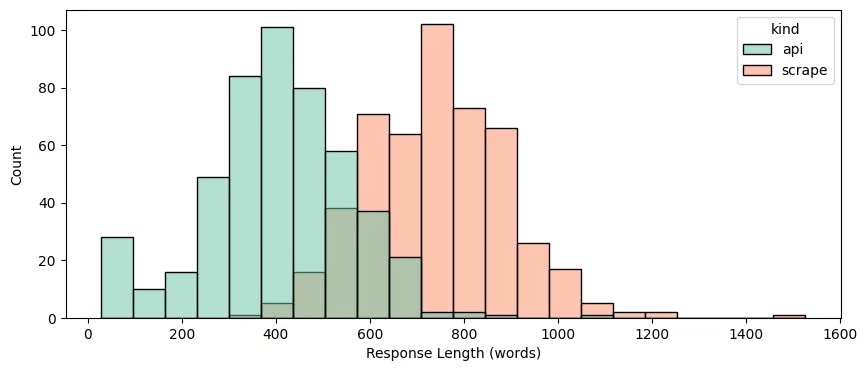
Longueur des réponses API vs résultats réels
- API : ~406 mots en moyenne
- Scrap réel : ~743 mots en moyenne: les API livrent souvent des réponses plus courtes et moins détaillées que ce que l’utilisateur voit vraiment.
Les réponses issues de l’API sont donc nettement plus courtes que celles récupérées via l’interface.
Déclenchement du Web search API vs résultats réels
- Dans ~23 % des cas, les API ne déclenchent pas de recherche Web alors que les vraies réponses le font.
- Les réponses “scrapées” contiennent plus de sources cités et plus diversifiées que les API.
Environ 23 % des réponses API ne lancent pas de recherche sur le Web, généralement lorsqu’elles font moins de 100 mots. En revanche, les réponses récupérées déclenchent systématiquement une recherche.
Sources des réponses résultats API vs résultats réels
Les API ne fournissent aucune source dans environ 25 % des cas. Les réponses générées par l’IA à partir de données scrapées fournissent toujours des sources, et environ deux fois plus (16 contre 7 en moyenne).
Détection de marque résultats API vs résultats réels
Les données issues de l’API ne détectent aucune marque dans environ 8 % des cas, tandis que les réponses récupérées identifient toujours des marques.
Lorsqu’une marque est détectée, l’API en identifie en moyenne davantage : 12 contre 9.
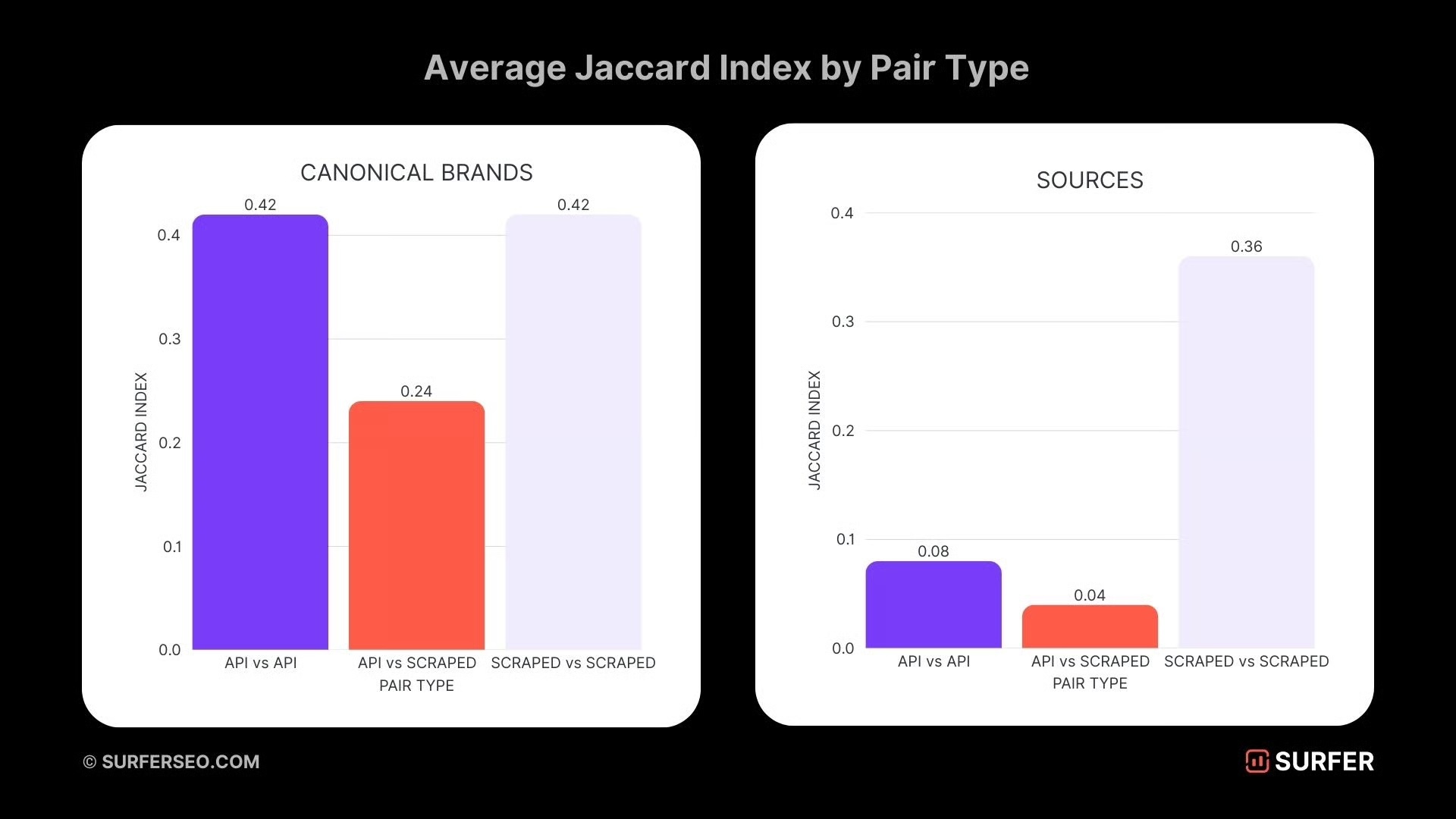
Les résultats API et les résultats ChatGPT sont-ils identiques ?
Alors, les résultats sont ils les mêmes résultats avec l’API et l’interface web/app ?
La réponse : non, absolument pas.
Les différences sont frappantes :
- Seules 24 % des marques détectées se recoupent entre l’API et le scraping.
- Pour les sources, le recoupement tombe à seulement 4 %.
D’accord, nous avons vu la différence entre les réponses récupérées par scraping sur ChatGPT et celles fournies directement par l’API. Voyons maintenant ce que donne Perplexity.
Perplexity : différences entre les résultats récupérés par scraping et ceux obtenus via l’API
| Aspect | Résultats API | Résultats récupérés (scraping) | Commentaire |
|---|---|---|---|
| Longueur des réponses | ~332 mots | ~433 mots | Les réponses API sont plus courtes et moins détaillées |
| Recherche Web | Toujours utilisée, mais certaines sources peuvent être omises, entraînant parfois l’absence totale de réponse | Toujours utilisée, toutes les sources présentes | Le scraping reflète l’expérience réelle de l’utilisateur |
| Sources citées | En moyenne 7 | Toujours 10 | Les réponses extraites contiennent systématiquement plus de sources |
| Mentions de marques | Généralement plus de 10 marques | Environ 6 marques ; 5 % des réponses remplacent les noms par des descriptions génériques | Les réponses API identifient plus de marques, mais certaines réponses extraites sont plus précises |
| Chevauchement API vs scraping | — | — | Seules 8 % des sources se recoupent entre l’API et le scraping, montrant des références souvent différentes |
Longueur résultats récupérés par scraping et ceux obtenus via l’API
Les réponses API sont plus courtes, avec une moyenne de 332 mots, contre 433 mots pour les réponses récupérées.
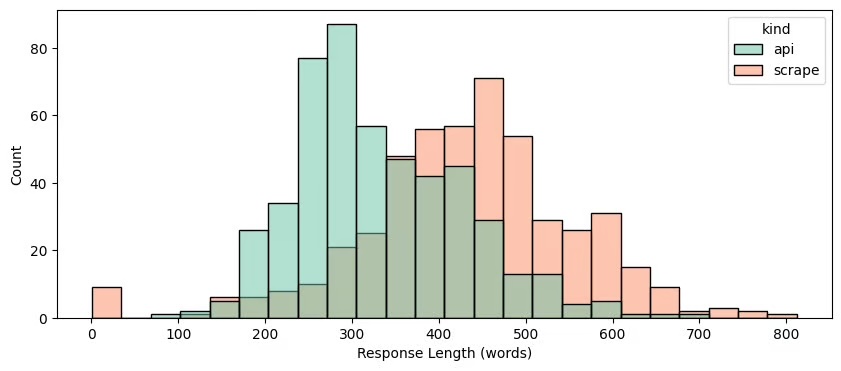
Recherche Web : résultats récupérés par scraping et ceux obtenus via l’API
Les deux méthodes utilisent systématiquement la recherche Web, mais l’API peut parfois omettre certaines sources, ce qui peut conduire à l’absence totale de réponse.
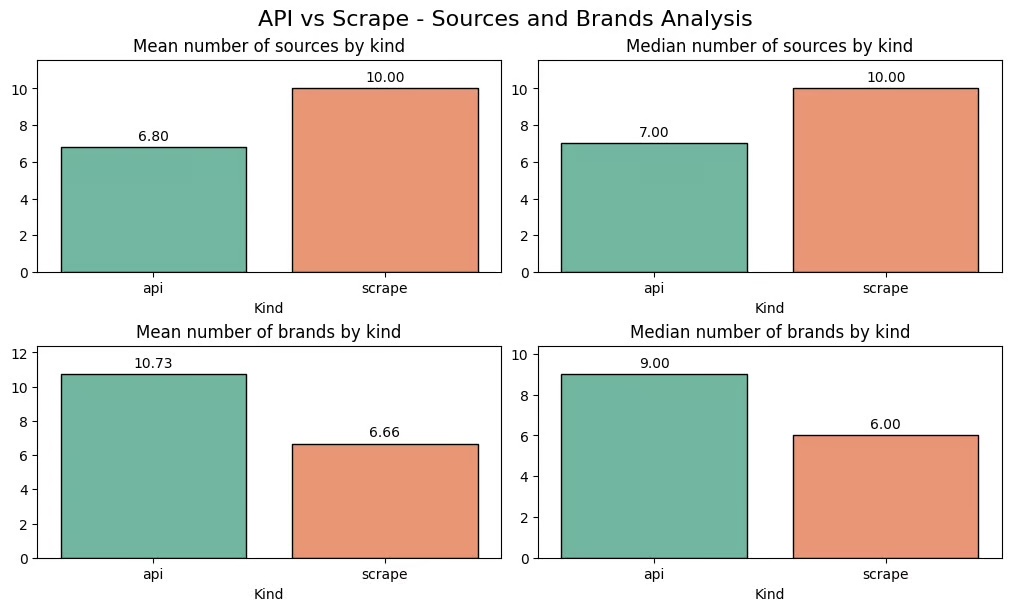
Sources : résultats récupérés par scraping et ceux obtenus via l’API
Les API renvoient en moyenne 7 sources, tandis que les réponses extraites en contiennent toujours 10.
Mentions de marques : résultats récupérés par scraping et ceux obtenus via l’API
Dans environ 5 % des réponses extraites, les noms de marques sont remplacés par des descriptions plus génériques. Les réponses API incluent généralement plus de 10 marques, contre environ 6 pour les réponses extraites.
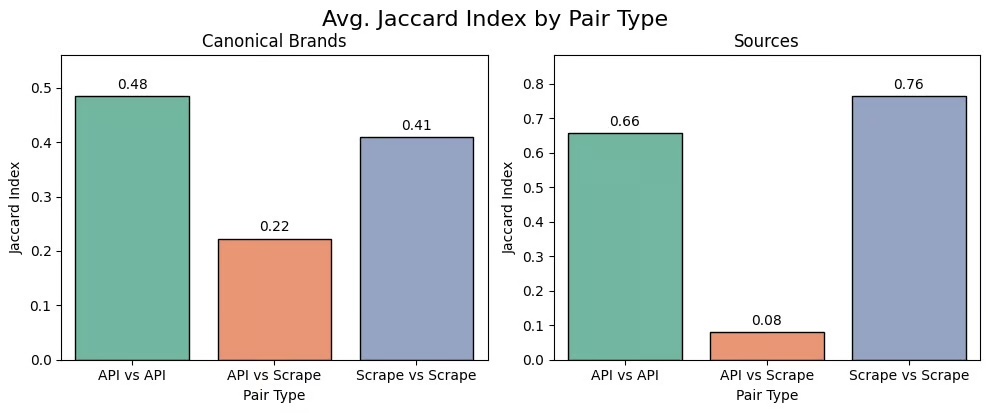
Les marques et les sources sont-elles similaires dans Perplexity ?
Encore une fois : NON.
Le chevauchement des sources n’est que de 8 %, ce qui signifie que l’API et l’interface utilisateur s’appuient souvent sur des références totalement différentes.
Ce que ça veut dire sur la fiabilité des outils de tracking
La majorité des outils de visibilité IA reposent sur les API des LLMs pour extraire des métriques (comme fréquence de mentions, présence dans LLM, visibilité, etc.). Mais l’étude montre que ces API ne reflètent pas fidèlement ce que les utilisateurs voient réellement dans l’interface des LLMs (ChatGPT, Perplexity, etc.).
Cela signifie que :
- Les métriques de tracking peuvent être biaisées ou incomplètes
- Elles peuvent sous-estimer ou surestimer la visibilité réelle
- Elles peuvent mal représenter la manière dont une marque ou un site est cité dans les réponses visibles
En bref : utiliser les API comme proxy unique pour mesurer la visibilité IA/LLM est, selon cette étude, insuffisant voire trompeur, ce qui explique ta méfiance vis-à-vis de ces outils.
Pourquoi l’API semble moins performante (et pourquoi c’est faux) ?
Un article de Gumshoe AI attaque l’idée que les API sont de facto moins performantes. Selon lui, l’écart entre API et UI vient surtout de l’absence des system prompts (messages système).

Le Rôle des « Messages Système »
Les messages système fonctionnent comme un directeur de publication invisible : ils ne font pas partie de la question de l’utilisateur, mais dictent à l’IA comment répondre. Ils contrôlent :
- Citations : ordre de citer les sources.
- Longueur : verbeux ou concis (d’où l’API brute souvent plus courte).
- Formatage : gras, listes, tableaux…
Gumshoe AI essaye de nous convaincre que l’etude de SurferSEO compare des pommes et des oranges :
- Elles comparent une API « nue » (paramètres par défaut, aucune instruction de comportement).
- À une Interface « habillée » (fortement guidée par des prompts système complexes).
Pour lui, l’API qui oublie citations ou marques n’est pas moins performante : elle manque juste des bonnes instructions.
Sauf que… SurferSEO a bien utilisé un modèle avec system prompt. Donc oui, article intéressant, mais c’est peut-être pas ça le vrai écart.
ils le disent noir sur blanc :
Nous avons testé deux scénarios, en exécutant 1 000 requêtes à chaque fois.
Tout d’abord, nous avons comparé les résultats obtenus à l’aide d’une API « propre ».
Ensuite, nous avons ajouté une variante : nous avons utilisé une invite système OpenAI divulguée sur GitHub.
Les résultats étaient presque identiques dans les deux cas, avec et sans l’invite système.Surfer SEO
Deux scénarios testés :
- Scraping UI vs API “propre”
- On compare ce que l’UI affiche avec ce que l’API renvoie par défaut, sans instructions supplémentaires.
- Objectif : mesurer l’écart de base entre UI et API.
- Scraping UI vs API avec system prompt
- On ajoute à l’API une invite système OpenAI divulguée.
- Objectif : voir si ça rapproche les résultats de l’UI.
Résultat : dans les deux cas, les résultats étaient presque identiques. L’écart ne vient donc pas forcément des system prompts.
API OpenAI vs ChatGPT : quelle est la différence ?
ChatGPT, c’est le modèle(API) brut plus :
- des instructions spéciales (system prompts),
- des flux de données supplémentaires,
- une logique d’interface,
- et quelques ajustements secrets connus seulement d’OpenAI.
Ces couches font que ChatGPT se comporte différemment de l’API, même avec exactement le même modèle.
Difference entre la collecte des réponses via API VS collecte des réponses via scraping
| Aspect | Web Scraping | API Access |
|---|---|---|
| But | Capturer l’expérience réelle de l’utilisateur | Accéder aux données de manière structurée et programmatique |
| Inclut | – Message final affiché à l’utilisateur- Mise en forme- Éléments interactifs de l’interface- Sources- Logique supplémentaire appliquée par la plateforme | – Réponses propres et structurées- Appel de fonctions- Formats cohérents |
| Ne fournit pas | Structure de données prête à l’emploi | Interface, comportement de recherche, sources, “magie” supplémentaire |
| Usage recommandé | Surveiller comment votre marque ou vos contenus apparaissent dans les outils AI | Construire des applications, automatiser des traitements ou des intégrations |
Si vous voulez comprendre les différences entre ces deux méthodes de collecte et leurs enjeux, je vous recommandel’article de SEO Clarity, qui les explique en détail.
Verdict ?
Pour la team de SEO clarity, quand il s’agit de GEO, le Scraping d’Interface est supérieur.
Pourquoi ? Parce que l’API manque de nuance. Dans la recherche IA, la visibilité ne dépend pas juste d’être mentionné dans le texte, mais d’être cité en tant que source cliquable. Seul le scraping permet de vérifier si votre marque est présentée comme une recommandation active avec un lien, ou simplement comme un mot dans un paragraphe de texte brut.
En résumé : l’API est idéale pour des données propres et rapides à grande échelle, mais elle est aveugle à l’expérience utilisateur réelle. Pour comprendre votre véritable visibilité dans l’IA, vous devez voir ce que l’utilisateur voit, et seul le scraping le permet.
En parlant de GEO(AEO pour eux), ils proposent une certification GEO gratuite pour le moment, que j’ai testée : courte, sympa et vraiment intéressante.
AEO Certification Certificate (16)
La difference entre réponses API vs réponses réelles sur Google AI Overviews
Google et ses solutions IA ne sont pas à l’abri du débat sur les différences entre réponses API et réponses « réelles ». Explication :
Writesonic a publié un excellent article qui met en lumière les divergences entre les réponses fournies via l’API et celles accessibles publiquement dans l’écosystème Google.
Le constat rejoint celui de SEO Surf : ce que les outils GEO voient via l’API n’est souvent pas ce que vos clients voient sur leur écran.
API : elle se base souvent sur des méthodes de classement classiques et des index parfois moins à jour. Elle renvoie des données brutes, structurées, mais incomplètes côté « réponse générée ».
UI (la vision humaine) : elle utilise des LLM qui synthétisent l’information en temps réel, offrant une réponse riche, contextuelle et personnalisée
Les 4 Raisons Techniques de la Discrépance
Writesonic identifie quatre facteurs clés qui expliquent pourquoi API et UI ne donnent pas les mêmes résultats :
- Algorithmes différents : l’API se base souvent sur des critères classiques (backlinks, mots-clés), alors que l’UI utilise des LLM pour synthétiser une réponse pertinente, pas juste classer des liens.
- Fraîcheur des données (RAG) : l’UI peut chercher des infos en temps réel grâce au RAG, là où l’API repose sur des index statiques mis à jour moins souvent.
- Personnalisation & contexte : l’UI prend en compte l’historique, la localisation et les requêtes précédentes. L’API, elle, reste « froide ».
- Post-traitement : l’UI nettoie et réécrit les résultats pour éviter doublons et biais, ce qui n’est pas fait pour les données brutes de l’API.
Mon avis sur la difference entre les réponses LLM API vs les résultats LLM scrapees
Honnêtement, ça ne me surprend pas. Dans mes audits SEO/GEO, je vois souvent que les réponses API ne collent pas à ce que le scraping révèle.
En clair : l’API, c’est scalable et safe, mais ça ne reflète pas l’expérience réelle. L’UI montre la réalité, mais c’est plus complexe et parfois risqué.
Perso, tout ce débat ne fait que me donner encore plus envie d’explorer la data IA directement via Search Console…
Sources
Les sources de qualité citées dans cet article sont rassemblées ici :
- https://surferseo.com/blog/llm-scraped-ai-answers-vs-api-results/
- https://blog.gumshoe.ai/how-apis-unlock-better-insights-into-ai-search-visibility/
- https://writesonic.com/blog/api-vs-ui-results

SEO/GEO consultant
Aslane SAMAI
- WebMCP : qu’est-ce que ce nouveau standard SEO/GEO pour la visibilité dans les LLM ?
- Le Chunking est il une technique pour optimiser SEO et GEO ?
- Top 10 des outils GEO pour suivre votre positionnement IA (2025)
- MCP Chrome DevTools & Google Analytics : indispensables pour GEO et LLMs
- Visibilité sur IA (Google mode IA, AI overviews, LLM) : les outils nous trompent ?
Laisser un commentaire