Tous les outils que je présente ici sont accessibles directement via ma page Streamlit : https://share.streamlit.io/user/aslan04739
Bulk Analyse de proximité sémantique
Si vous faites du GEO ou du SEO sémantique, vous analysez normalement la proximité sémantique entre vos requêtes et vos URLs.
Enfin… j’espère.
Sur Screaming Frog, on peut faire ce check. Le problème : c’est un par un. Et impossible de comparer facilement vos URLs avec celles d’un concurrent.
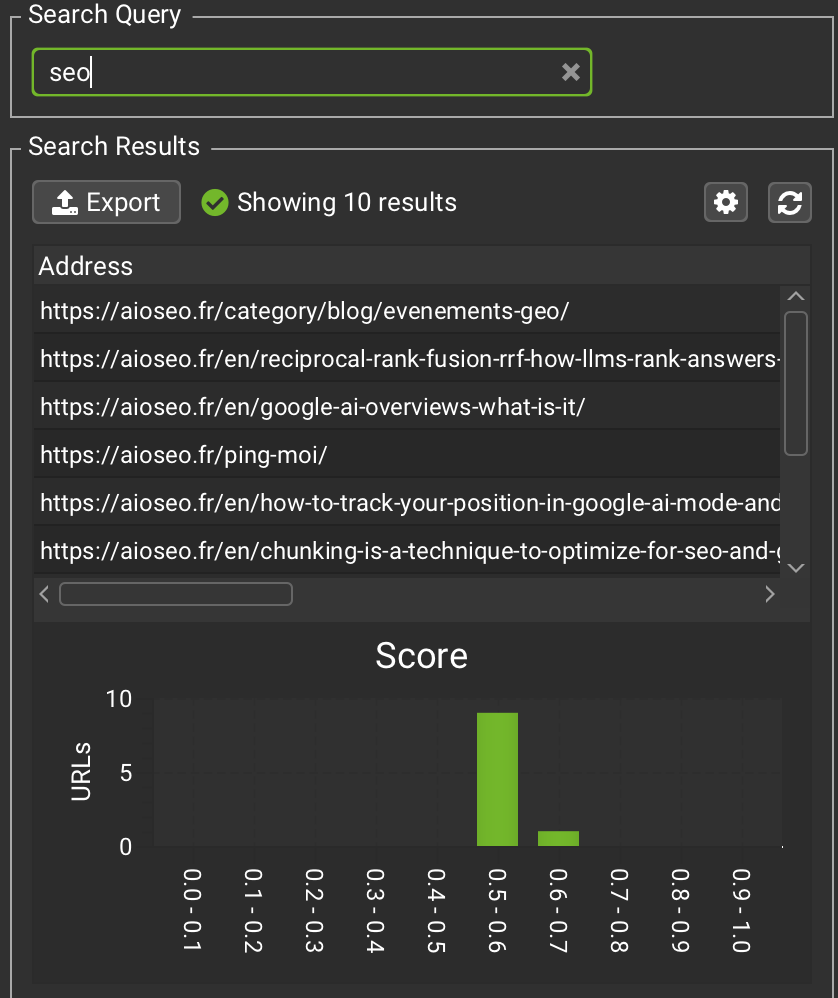
Du coup, j’ai codé un premier outil pour régler ce problème. Un outil pour faire un calcul de proximité sémantique VS celui d’un concurrent de votre choix.
Puis j’ai eu un autre besoin : le faire en bulk.
Donc j’ai codé un deuxième outil.
La méthode est différente, mais l’objectif reste le même : savoir si Google associe les bonnes pages aux bonnes requêtes.
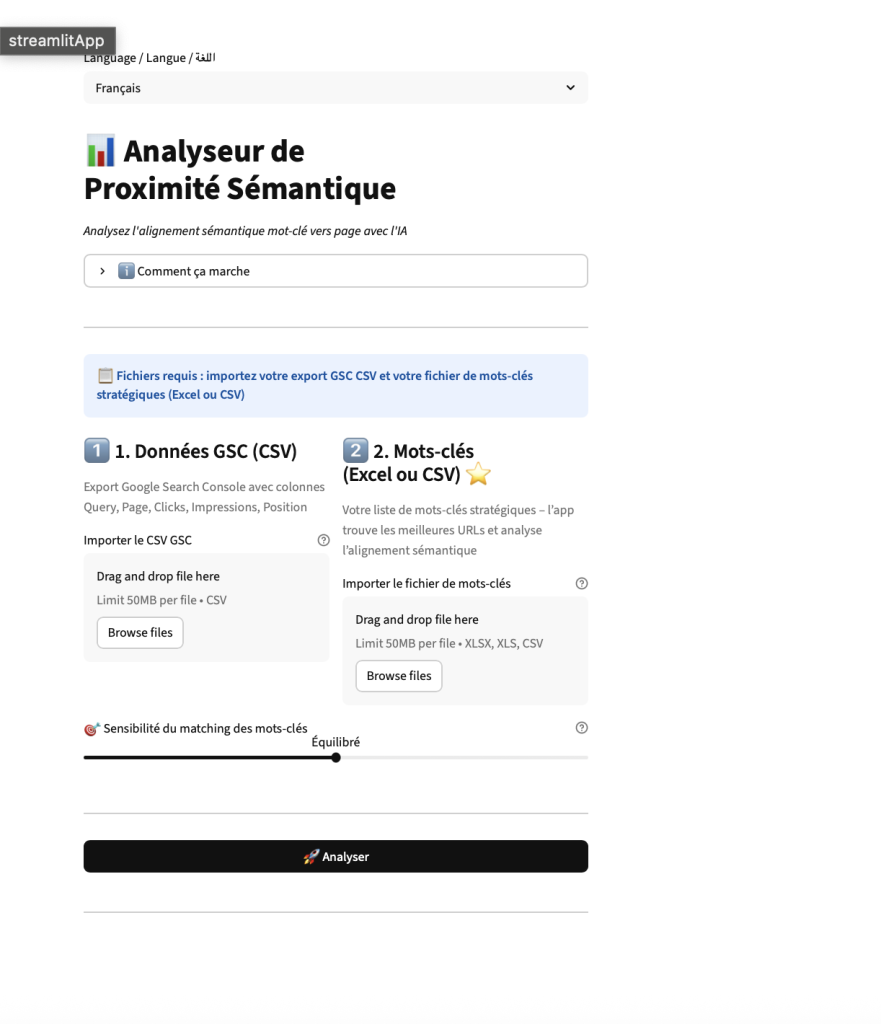
Comment fonctionne le Bulk Analyse de proximité sémantique ?
Le process est simple.
- Vous avez un sheet / Excel / CSV de vos mots-clés prioritaires (si vous n’en avez pas, commencez par là).
- Vous exportez vos données Google Search Console avec le filtre query + page. Personnellement, j’utilise l’extension Search Analytics for Sheets. Indispensable.
- Vous importez les deux fichiers dans l’outil.
Et vous obtenez :
- les URLs qui rankent pour vos requêtes
- le score de proximité sémantique pour chaque URL
Les scénarios possibles
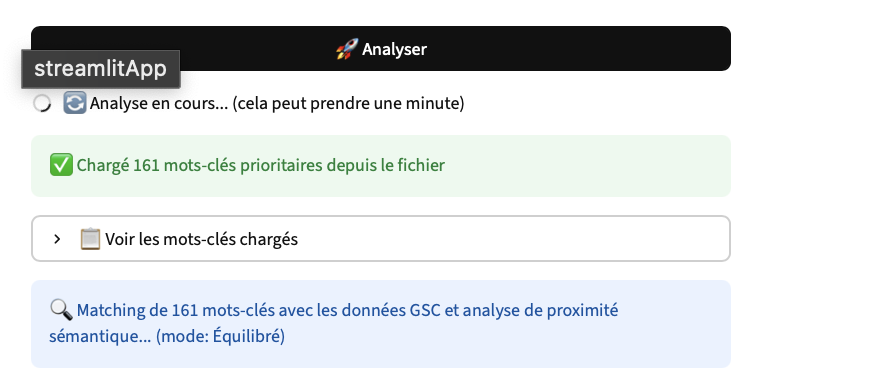
Apres l’analyse, vous deux scénarios :

Soit l’outil arrive à fetch vos URLs.
Dans ce cas, on va analyser :
- le slug
- les balises
- et surtout le contenu de la page
C’est là que le score de proximité sémantique devient vraiment pertinent.
Sinon, il arrive que l’outil ne puisse pas récupérer la page (blocage, timeout, JS, etc.).
Dans ce cas, on se base uniquement sur une comparaison entre l’URL et la requête.
Ce n’est clairement pas idéal, mais ça permet quand même d’avoir un premier signal.

Quand l’outil arrive à fetch les URLs, plusieurs scénarios peuvent se présenter.
1. Les bonnes URLs rankent et les scores sont bons
Rien à signaler.
Google comprend votre page et l’associe correctement à la requête.
2. Les bonnes URLs rankent mais les scores sont faibles
Il y a probablement un travail d’optimisation on-page à faire : contenu, balises, structure sémantique.
3. Les mauvaises URLs rankent
Typiquement la home ou une page générique.
Souvent un problème de pertinence sémantique sur la page cible.
4. Aucune de vos URLs pertinentes ne ranke
Dans ce cas, le problème dépasse la sémantique : autorité, structure du site, intention de recherche mal couverte, etc.
Bref, le score ne sert pas juste à faire joli.
Il vous aide surtout à comprendre pourquoi Google associe (ou non) une page à une requête.
Analyseur d’entités SEO (SEO Entity Analyser)

L’analyse manuelle des entités est inefficace à l’échelle. J’ai développé cet outil pour automatiser l’audit sémantique via l’API GPT.
Fonctionnement
L’outil croise les données de vos URLs avec un modèle JSON via l’API pour extraire et vérifier la présence et la pertinence des entités instantanément.
Features
- Single URL : Audit d’entités immédiat.
- Bulk Mode : Import de liste d’URLs avec gestion de la profondeur (depth).
Pourquoi utiliser l’analyseur d’entités pour les consultants SEO & GEO ?
- Alignement LLM & SGE : Les moteurs génératifs (ChatGPT, Google SGE/AIO) raisonnent via le Knowledge Graph, pas par mots-clés. Utiliser l’API GPT permet d’auditer vos contenus avec la même logique que les moteurs qui les jugent.
- Entity Salience & Disambiguation : Vérifiez si vos entités principales sont correctement détectées et disambiguïsées pour maximiser vos chances de citation dans les réponses générées par IA (GEO).
- Topical Authority à l’échelle : L’audit manuel ne permet pas de valider la cohérence sémantique d’un cluster entier. Le mode bulk assure que votre maillage d’entités est solide sur l’ensemble de la structure, pas juste une page.
Outil gratuit, développé pour mes propres besoins de consulting. Essayez le !
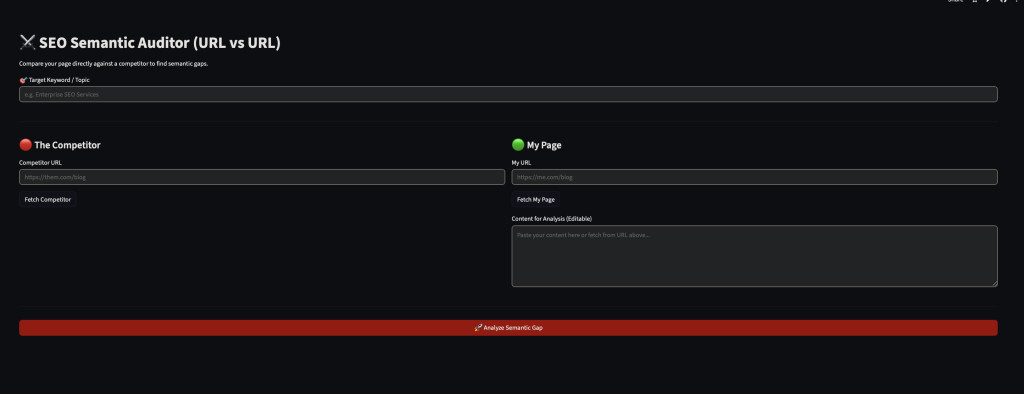
Auditeur sémantique SEO (URL vs URL)
Pourquoi une page ranke devant la vôtre ? La réponse ne se trouve plus seulement dans les backlinks ou la densité de mots-clés. Que ce soit les moteurs classiques (Google via RankBrain/BERT) ou les moteurs génératifs (Gemini, Perplexity, ChatGPT Search), ils partagent désormais la même logique fondamentale : la proximité vectorielle.
Ils ne font pas du « word matching », ils projettent votre contenu dans un espace sémantique multidimensionnel. Si votre vecteur est trop éloigné de celui de la requête, vous n’existez pas pour le retriever du LLM, ni pour le ranking de Google.
J’ai développé cet outil pour auditer cette distance mathématique exacte.
La Stack Technique
L’outil s’appuie sur :
- Vectorisation (
all-mpnet-base-v2) : Le modèle SOTA actuel desentence-transformers. Il encode le contexte profond de votre page pour simuler la compréhension d’un moteur moderne. - Extraction (
KeyBERT) : Pour isoler les entités et n-grams qui constituent l’ossature sémantique du contenu concurrent.
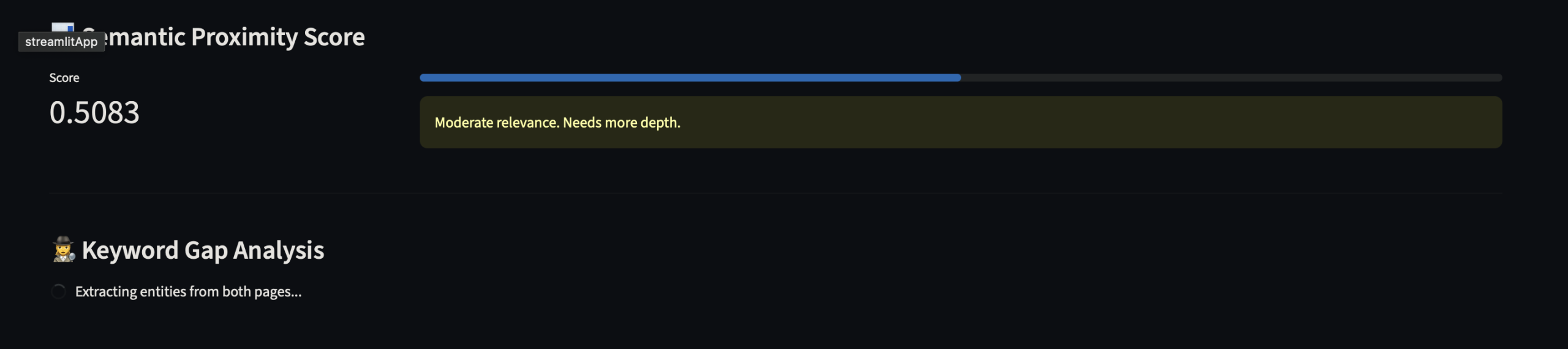
Les KPI de l‘auditeur sémantique
1. Semantic Proximity Score (Distance Cosinus) C’est la mesure brute de votre alignement avec l’intention de recherche (le « prompt » de l’utilisateur).
- Pour le SEO (Google) : Un score élevé indique que vous répondez précisément à l’intention latente.
- Pour le GEO (LLMs) : C’est crucial pour le RAG (Retrieval-Augmented Generation). Plus votre proximité est forte, plus vous avez de chances d’être sélectionné comme source dans une réponse générée par IA.
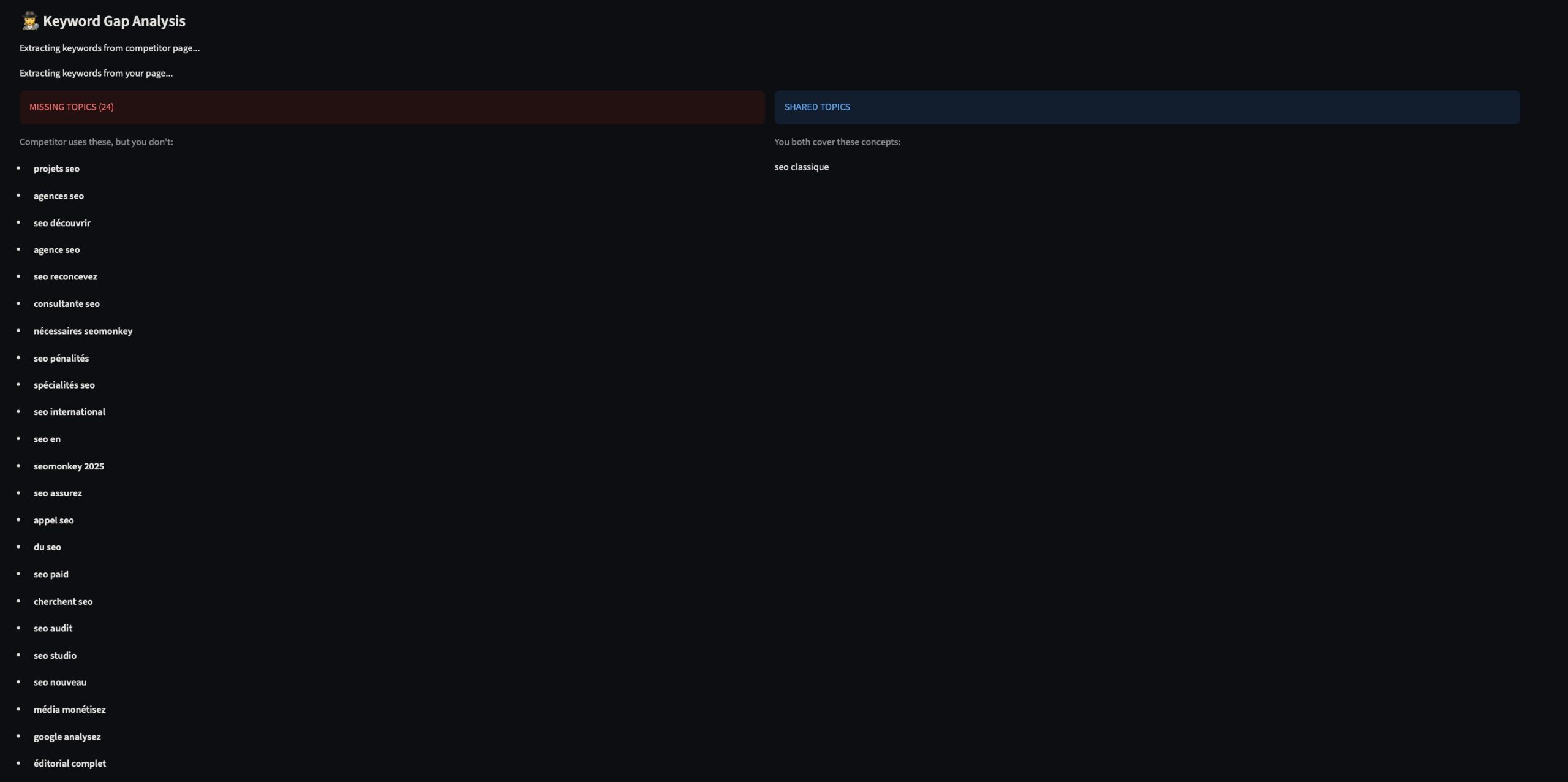
2. Gap Analysis (Missing Entities)
L’auditeur sémantique compare votre vecteur à celui du concurrent sélectionné.
- L’output : Il identifie les concepts sémantiques présents chez le concurrent mais absents chez vous. Ce sont les « trous » qui empêchent votre vecteur de s’aligner parfaitement avec la requête.
Pro Tip :
Ne visez pas la copie. Visez le Delta Positif.
Score cible : Entre 0.65 et 0.80.
Pourquoi pas 1.0 ? Une identité parfaite est suspecte. L’objectif est de couvrir le champ sémantique (les entités manquantes identifiées par l’outil) pour réduire la distance vectorielle, tout en gardant votre angle unique. C’est ce qui vous permet de ranker sur Google ET d’être cité par les IAs.
Auditez la sémantique de vos pages
Fonctionnement de l’auditeur sémantique
- Input Target & Benchmark : Vous définissez le mot-clé cible et les deux URLs à comparer : votre page vs celle du concurrent.
- Fetching & Cleaning : L’outil scrape les URLs, parse le DOM et nettoie le bruit (menus, footers, scripts) pour isoler uniquement le contenu textuel significatif.
- Vectorisation & Analyse : Le moteur (
all-mpnet-base-v2) transforme les deux textes et le mot-clé en vecteurs denses pour comprendre le contexte profond, au-delà des simples mots. - Scoring (Proximity Score) : Calcul de la similarité cosinus entre votre vecteur et celui de la requête cible. Vous obtenez un score de pertinence brute (0 à 1).
- Gap Analysis (Missing Entities) : Via KeyBERT, l’outil extrait les n-grams/entités performants chez le concurrent et filtre ceux qui sont absents de votre contenu.
- Résultats Actionnables : Vous obtenez la liste précise des concepts sémantiques à intégrer pour combler le fossé vectoriel avec le leader.
Outil de prévision du trafic SEO – (SEO Forecaster) – Powered by Google TimeSFM
En prédiction de trafic SEO, les droites de tendance et les moyennes mobiles ne tiennent pas dès qu’un update ou une saisonnalité un peu complexe entre en jeu.
J’ai codé cet outil car je voulais tester une approche plus robuste pour mes forecasts Search Console. L’idée est d’appliquer l’architecture Transformer aux séries temporelles SEO.
La stack technique
L’outil tourne sur TimeSFM (Time Series Foundation Model) de Google Research. C’est un modèle de type « decoder-only transformer » entraîné sur un corpus massif de 100 milliards de points de données (séries temporelles).
Prévoyez votre trafic SEO avec Google TimeSFM
Pourquoi ce model pour la prediction du trafic SEO ?
- Capacité Zero-Shot : Contrairement aux modèles statistiques (ARIMA) qui nécessitent un tuning fin pour chaque propriété, TimeSFM généralise immédiatement sur de la nouvelle data. Il digère votre export GSC et identifie les patterns sans entraînement préalable.
- Contexte long : Le modèle gère des fenêtres contextuelles étendues. Il est capable d’ingérer l’historique complet de la GSC (16 mois) pour détecter des cycles de saisonnalité complexes ou des ruptures de tendance que les méthodes classiques lissent trop.
- Google sur Google : Il y a une certaine cohérence logique à utiliser un modèle de fondation Google pour prédire des métriques (Impressions, Clics, CTR) issues de l’écosystème Google.
Comment sa fonctionne ?
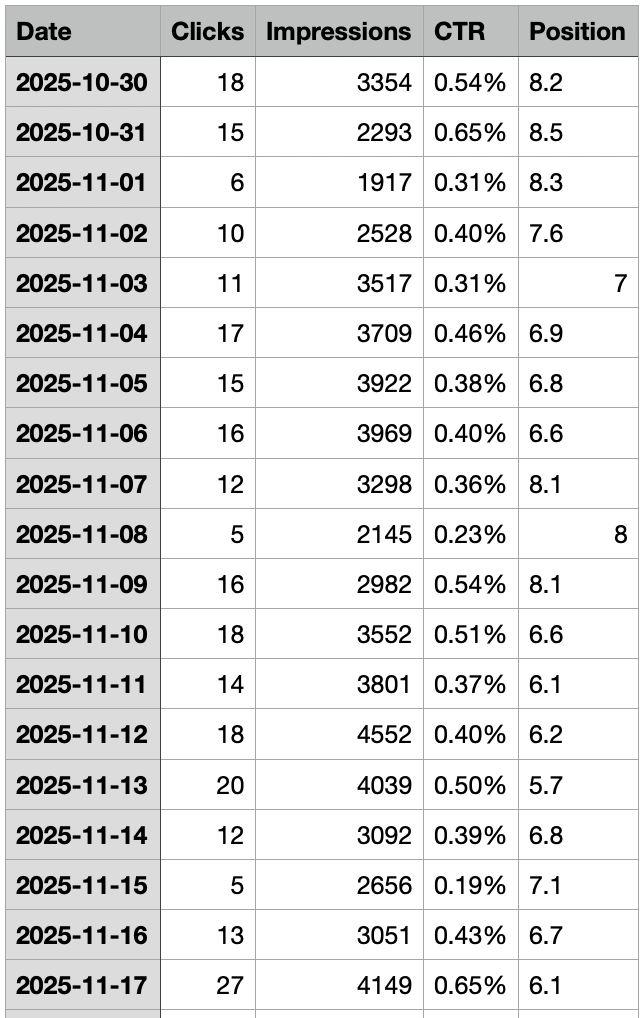
Concrètement, vous droppez votre CSV Search Console avec les colonnes date(tres important), impressions, clics, CTR et position. Voici un échantillon du dataset utilisé dans cet exemple
Le script envoie la data au modèle et vous sort les prédictions (Trafic, CTR, Positions) avec une précision SOTA (State of the Art).
Côté paramètres, en pratique, il n’y a quasiment rien à ajuster : uniquement l’horizon de prédiction. Que ce soit 30 jours, 3 mois ou un an, le reste du modèle reste figé.
Résultats de Google Owner avatar
timesfm
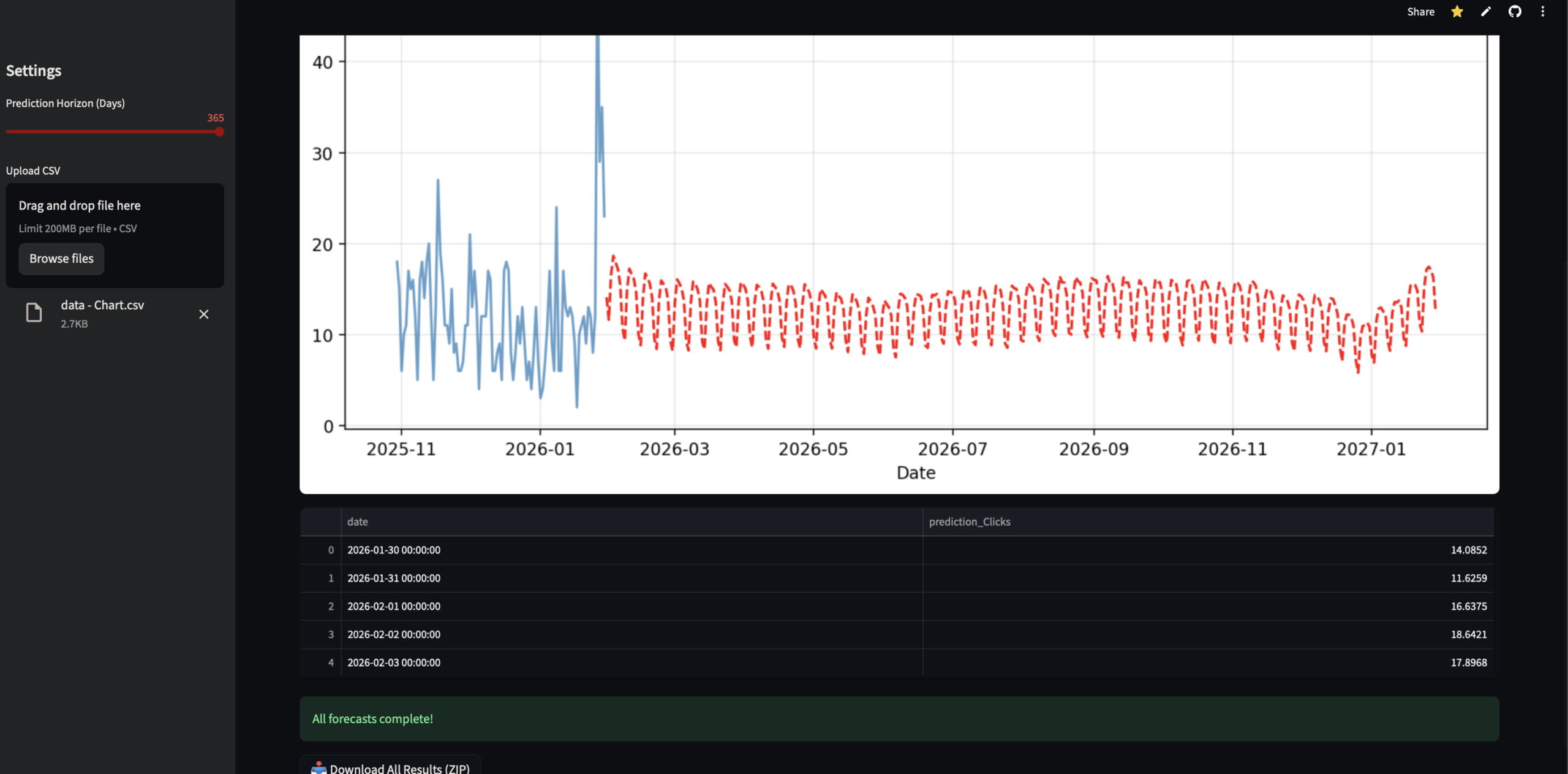
L’outil fournit quatre sorties :
- une prédiction des clics (tableau + graphique)
- une prédiction des impressions (tableau + graphique)
- une prédiction du CTR (tableau + graphique)
- une prédiction de la position moyenne (tableau + graphique)
PS : les résultats sont bien évidemment téléchargeables.
3. Outil de prévision du trafic SEO (SEO Forecaster) – Powered by Meta Prophet
Une tendance n’est jamais juste une ligne droite : elle subit les week-ends, les vacances et les événements cycliques. Essayer de modéliser ça manuellement sur Excel est une perte de temps, et les moyennes mobiles lissent trop la réalité pour être exploitables.
Pour ceux qui ont besoin de maîtriser ces cycles, j’ai implémenté Prophet, le modèle de prévision open source développé par l’équipe Core Data Science de Meta.
Le stack technique
L’outil tourne sur Prophet de chez Meta.
Contrairement aux approches « Black Box » (comme les réseaux de neurones profonds), Prophet est un modèle de régression additive. Il ne se contente pas de lisser une courbe, il la décompose mathématiquement en trois briques intelligibles : la tendance de fond (Trend), la saisonnalité (hebdomadaire/annuelle) et les effets calendaires (Holidays).
Prévoyez votre trafic SEO avec Meta Prophet
Pourquoi Meta Prophet pour la prediction du trafic SEO ?
- Prophet utilise un modèle additif decomposable. C’est de la stat robuste conçue pour les données « business » réelles.
- Gestion native de la saisonnalité : le modèle décompose votre trafic GSC en trois composantes : Tendance (Trend) + Saisonnalité (Hebdo/Annuelle) + Jours fériés (Holidays).
- Changepoint Detection : L’algorithme détecte automatiquement les ruptures de tendance (ex: un Core Update ou une migration) là où une régression linéaire continuerait bêtement sur sa lancée.
- Robustesse aux outliers : Il gère parfaitement les « trous » de données (fréquents dans la GSC) ou les pics aberrants sans faire dérailler toute la prédiction.
Meta Prophet est l’outil parfait si votre trafic est très cyclique (e-commerce, news, saisonnier).
Il intègre les effets « jours de la semaine » (baisse le dimanche, hausse le lundi) dans ses forecasts.
Comment sa fonctionne ?
Concrètement, vous droppez votre CSV Search Console avec les colonnes date(tres important), impressions, clics, CTR et position. Le script envoie la data au modèle et vous sort les prédictions (Trafic, CTR, Positions) avec une précision SOTA (State of the Art).
Côté paramètres, en pratique, il n’y a quasiment rien à ajuster : uniquement l’horizon de prédiction. Que ce soit 30 jours, 3 mois ou un an, le reste du modèle reste figé.
Résultats de Meta Prophet
L’outil fournit quatre sorties :
- une prédiction des clics (tableau + graphique)
- une prédiction des impressions (tableau + graphique)
- une prédiction du CTR (tableau + graphique)
- une prédiction de la position moyenne (tableau + graphique)
PS : les résultats sont bien évidemment téléchargeables.
PPS : les deux tests ont été réalisés à partir du même jeu de données.
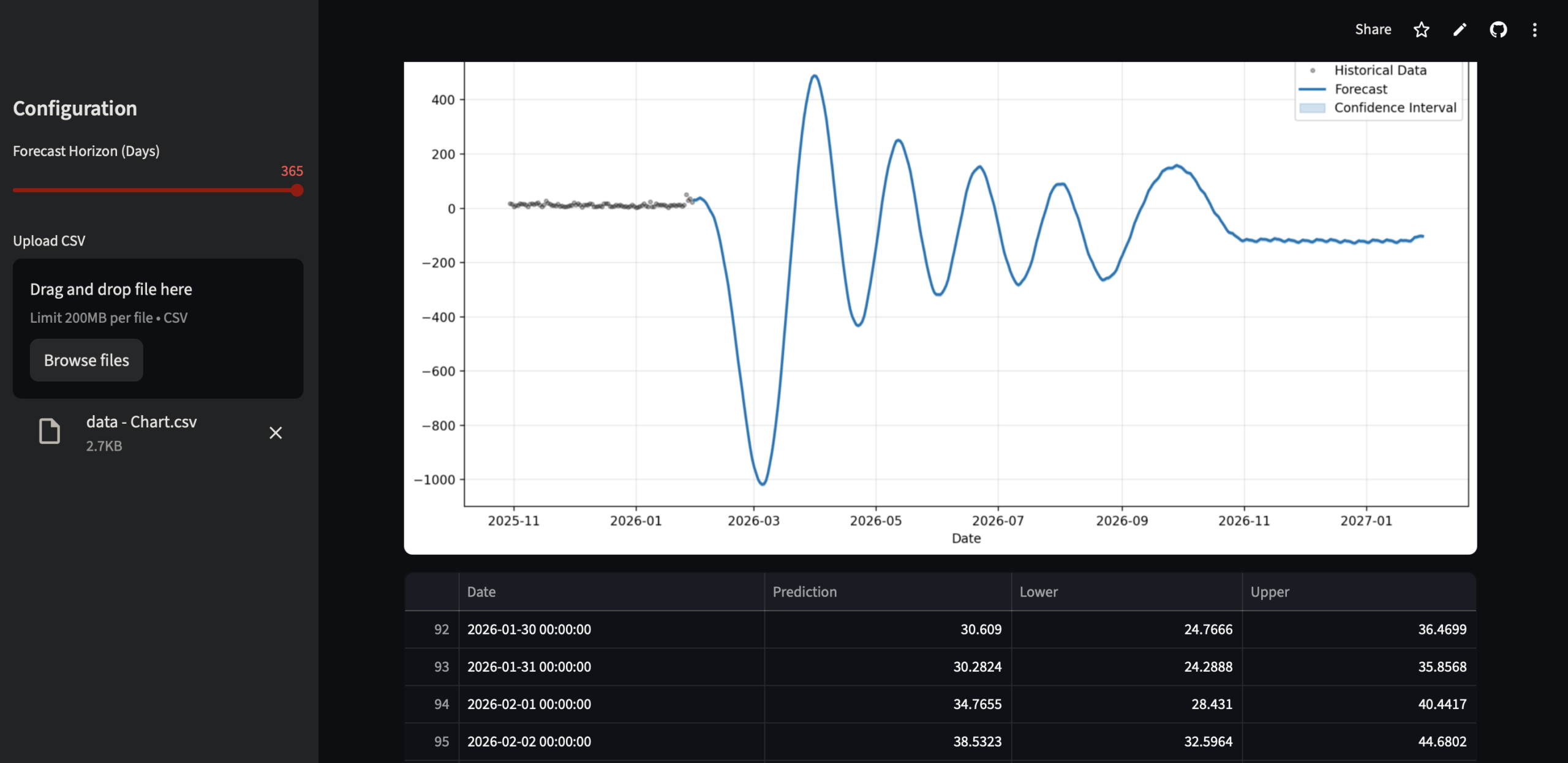
Comparatif Meta Prophet VS Google TimesFM
Meta Prophet (courbe bleue)
Ce qu’on observe
- Explosion des valeurs : pics très élevés et surtout valeurs négatives massives (jusqu’à -1000).
- Oscillations très amples, type sinusoïde non réaliste.
- Rupture brutale juste après la fin de l’historique.
Interprétation
- Prophet sur-interprète la saisonnalité avec trop peu de données.
- Il extrapole une structure (trend + seasonal) qui n’existe pas réellement dans l’historique.
- Le modèle n’est pas contraint sur le domaine des valeurs → il accepte des clicks négatifs (ce qui est économiquement absurde).
Prophet est parti un peu en vrille : instable, mal calibré pour une série courte et bien bruitée.
En l’état, le forecast n’est pas vraiment exploitable, sauf à y passer du temps (log transform, caps, priors, virer certaines saisonnalités, etc.).
Google TimesFM (courbe rouge)
Ce qu’on observe
- Valeurs toujours positives, dans le même ordre de grandeur que l’historique.
- Oscillation régulière et modérée (probablement hebdomadaire).
- Légère tendance molle, sans rupture brutale.
- Continuité propre entre historique et forecast.
Interprétation
- TimesFM lisse correctement le bruit.
- Il capte une saisonnalité courte sans la sur-amplifier.
- Le modèle reste conservateur → pas de pics délirants.
Le forecast de Google TimesFM est propre, crédible et directement exploitable, même s’il reste un peu prudent.
Verdict
- Prophet est un modèle structurel : il a besoin de long historique propre et d’hypothèses fortes. Apparement 16 mois de data ne suffisent pas. Cela dit, j’avoue que quand on joue avec les paramètres, le rendu est souvent plus réaliste…
- TimesFM est un model zero shot entrainé sur
sur des volumes massifs.
Sur une petite série de clicks bruitée, TimesFM gagne clairement.