January 30, 2026
Google has recently expressed via John Mueller (that I met in Zurich during a Search Central) and Danny Sullivan in the podcast, Google Search Central : according to them, the chunking would not be an approach truly beneficial.
Your browser can’t play this video.
Learn more
They recognize that the technique works today for the GEO. But according to Google, this is not a sustainable strategy, and it would, therefore, not the blow to rework the content to adapt it to the LLMs as a Gemini, ChatGPT or Perplexity.
Like any good SEO knows, the statements of Google will take it with a grain of salt…
It is the ground.
The Chunking is a technique to optimize SEO and GEO ?
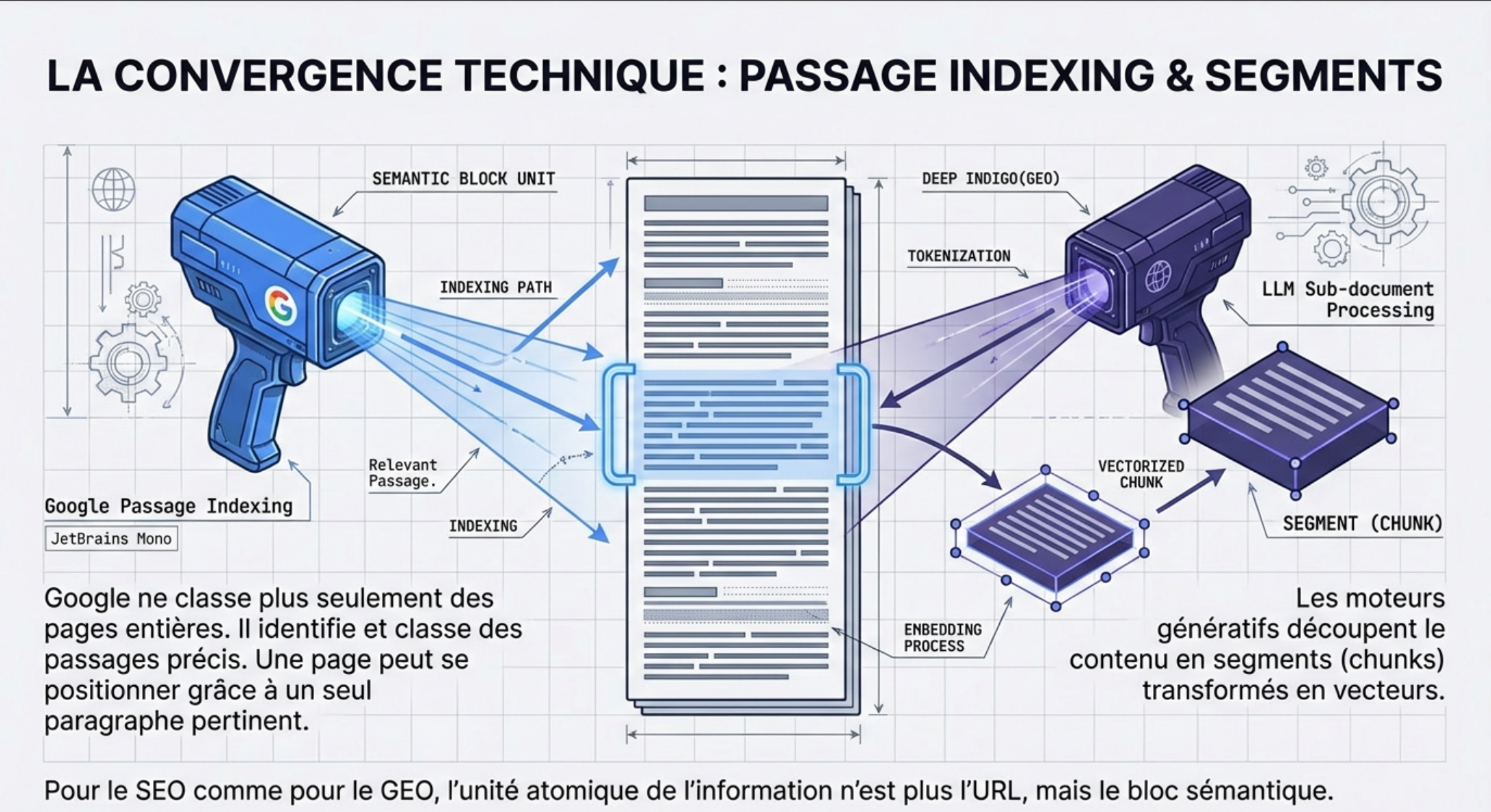
Google uses the passage indexing
On one side, we know that Google uses the passage indexing.
In practical terms, it means that Google is able to assess a page solely as a whole block, but also to identify and classify specific passages within a piece of content.
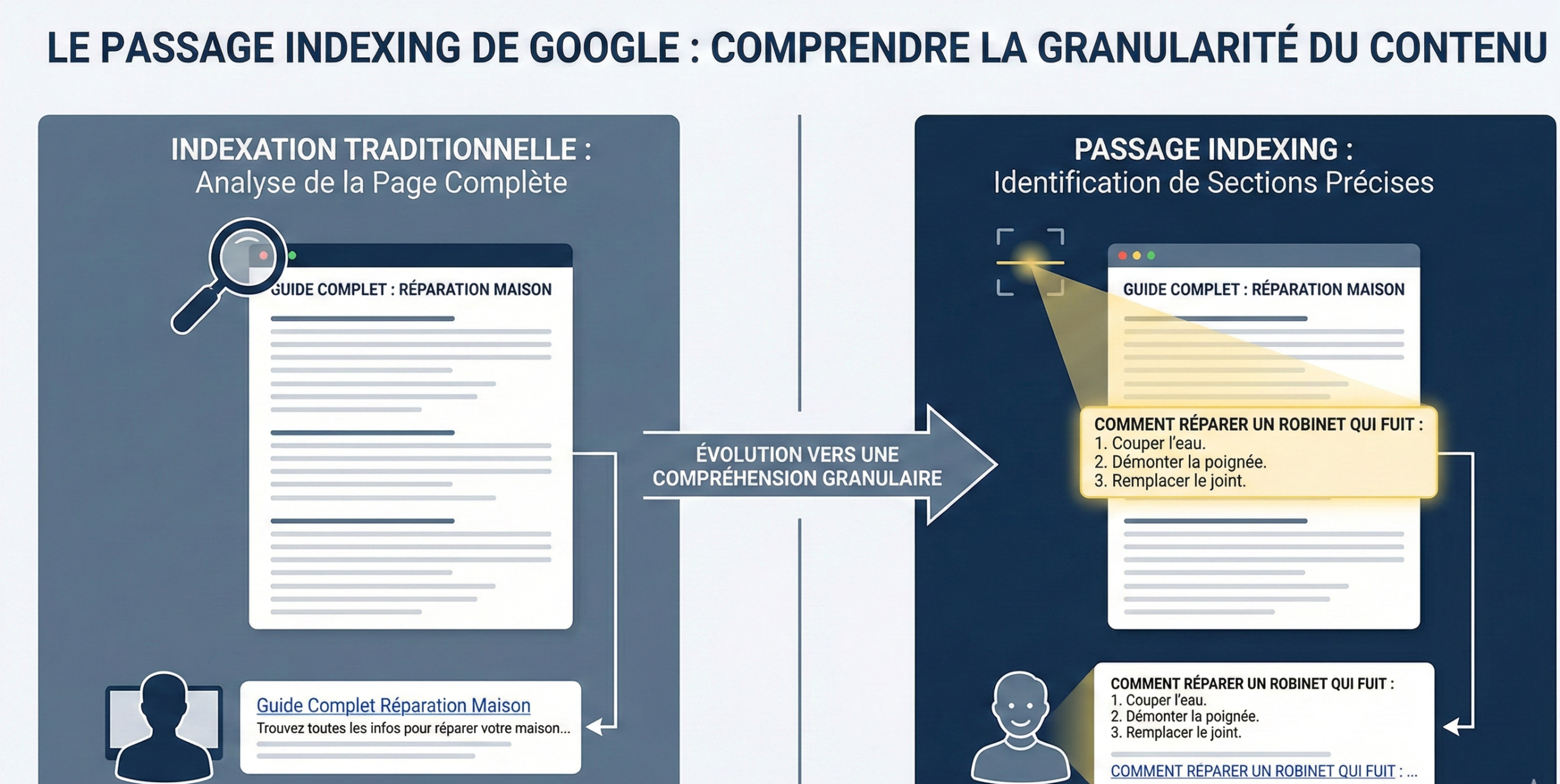
A page can be positioned through a paragraph very relevant, even if lhe rest of the content is wider or less focused. Google does not “see” more just pages, it also sees pieces of the pages.
Starting from this principle, I say to myself that the chunking, that is, by definition, the creation of independent blocks, semantiwquemrnt relevant, digestible, etc., using Google to identify their blocks for the passage indexing. If it does not help, it can’t hurt…
The LLMs use the sub document processing
On the other side, the LLMs operate with what is called the sub-document processing.
Instead of indexed pages, the engine is indexing extracts specific and granular. An extract, in the jargon of the AI, corresponds to approximately 5 to 7 tokens, that is 2 to 4 words, converted by the following figures.
When you query a system of sub-documents, it does not recover 50 documents, but about 130 000 tokens extracts the most relevant (about 26 000 extracts) to power the AI.
Specifically, the engines generative as perplexity, chatgpt, gemini, etc., does not consume a page like a human that reads from top to bottom. The content is broken into segments (chunks), transformed into vectors, and then stored in databases and semantic indexing.
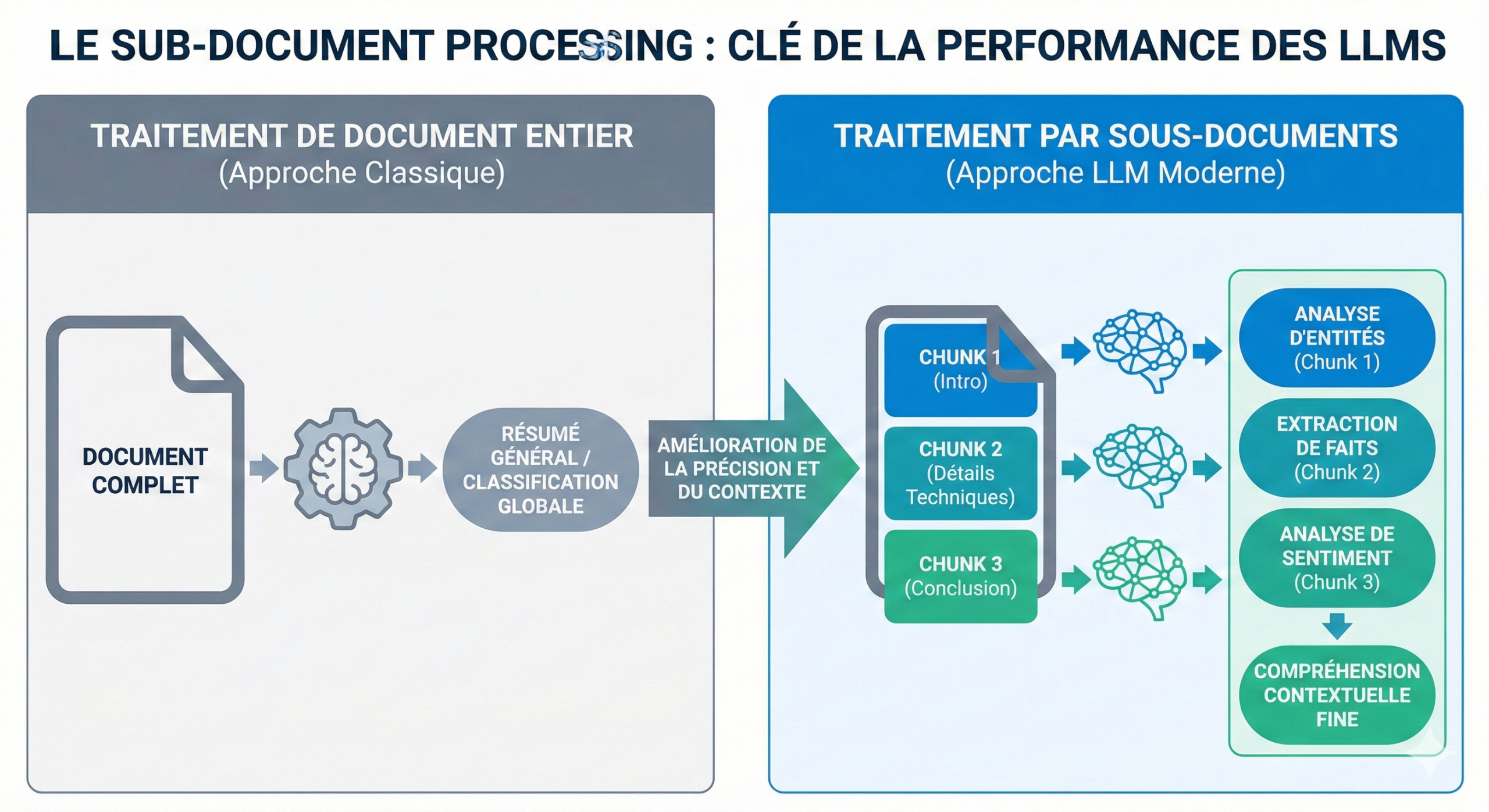
When a question is asked, the model does not “seek not a single page” :
it retrieves the pieces of text that are most relevant, no matter where they come from.
How does the sub document processing ?
A recent article – maintenance of Search Engine Journal with Jesse Dwyer of Perplexity, explains how they use the sub document processing.

Jesse talks about ‘ Saturation of the Window, Context, (window context saturation) : instead of getting 50 documents, the system recovers approximately 26 000 snippets relevant (i.e. ~130k tokens) to fill to the brim the window of the context of the LLM.
The goal ? ‘Saturate’ the model with so much of the relevant facts that it has no more space, ‘neural’ available to hallucinate or invent facts.
‘ The biggest difference in the search for AI today is in the treatment of ‘sub-documents’ (sub-documents) as opposed to the entire document. […] The approach ‘AI-first’ is the index of the extracts specific and granular rather than entire pages. ‘Jesse Dwyer
Difference between Google indexing and indexing LLMs ?
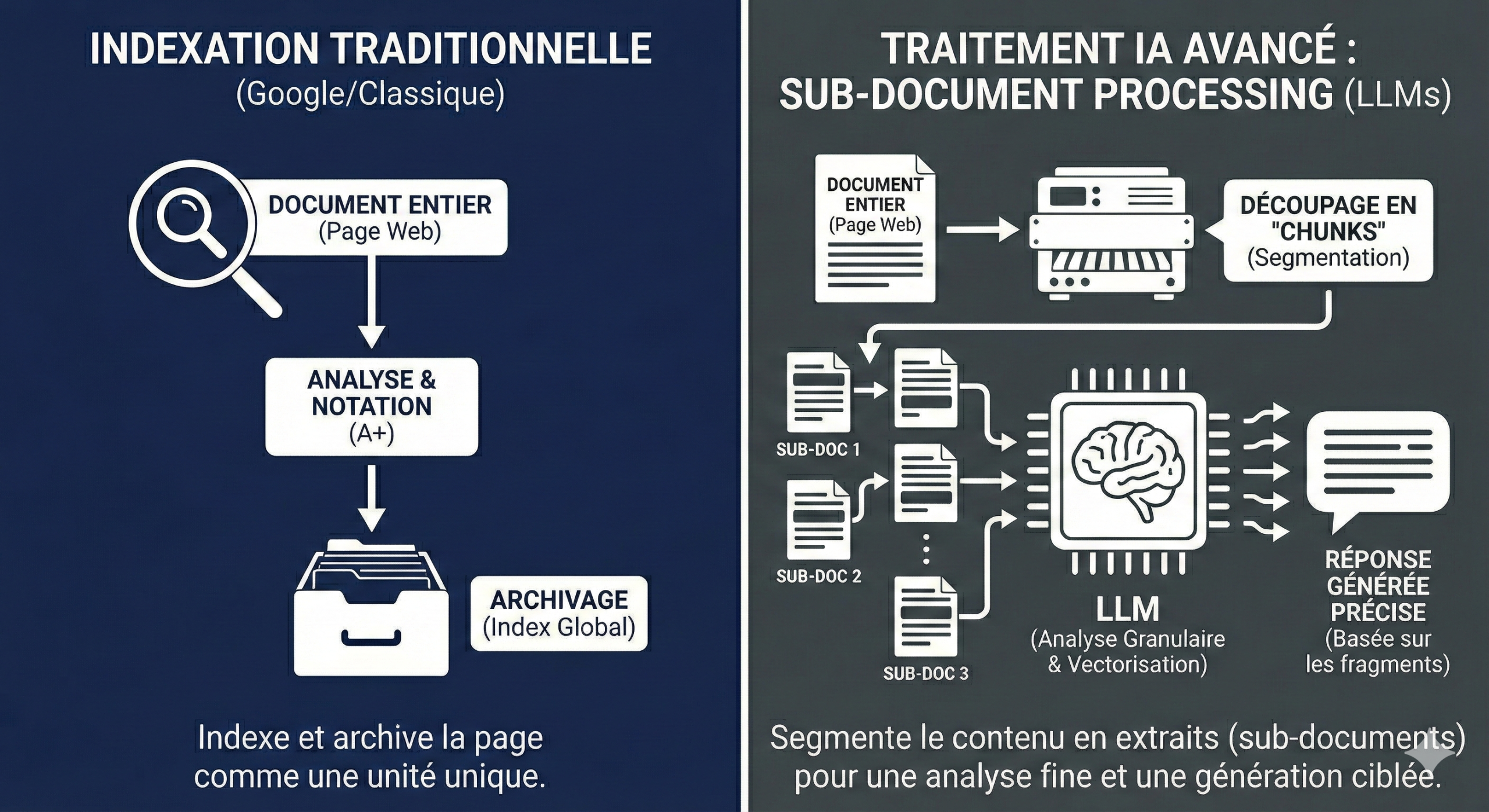
Traditional search engines index the entire document. They look at a web page, assign him a note and put it away.
When you use a tool that is AI, it performs the search for a classic, gets the 10 to the first 50 documents, and then asks the LLM to generate a summary.
| Indexing Traditional (Google / ‘ Whole-Document ‘) | Indexing IA (Native Perplexity, / ‘ Sub-Document ‘) | |
| Unit of Indexing | The URL (The Web Page). The engine indexes, notes and class to a HTML document as an indivisible unit. | The ” Snippet ” Vectorized. The unit is a piece of text (approximately 5-7 tokens or 2-4 words according to Dwyer, converted into digital vectors (embeddings). |
| Method of Retrieval (Retrieval) | Document classification (Ranking). The engine identifies the 10 to 50 best pagesbased on global signals (PageRank, Hn, Backlinks). | Research Vector Fragments. The system does not look for pages, it ‘sucks’ about 26 000 snippets relevant across the whole corpus indexed. |
| Volume of Data Processed | Low density. The AI (if used as an overlay type ‘ Bing Cat ‘) only reads the summary of top records. This is the approach of ‘ 4 Bing searches in a trenchcoat ‘. | Saturation of the Window Context. The goal is to recover ~130 000 tokens to fill 100% of the window’s context LLM. |
| Management of Hallucination | Low. If the source document contains errors, or if the summary is incomplete, the AI must ‘invent’ to fill the holes. | Maximum (Saturated). By saturating the window context with facts granule, don’t let ‘ no place neuronal ‘ the model to invent (hallucinate). |
| The role of the ‘ Container – ‘ (The Page) | Crucial. The structure of the page (Hn, markup) gives the meaning. The context is defined by the page itself. | Secondary. The page is only one source. The meaning is reconstructed by the association of thousands of snippets from disparate sources. |
The table compares the indexing classic Google (with a lot of simplification) with indexing so-called sub document of the LLMS.
But if we take into account the shift indexing of Google, the logic is the same : Google as the LLMs analyze the content to the scale of the passage, not only of the entire page.
Therefore, a chunking own and logic can’t really “clashing” of these systems. It goes rather in the sense of their way of processing information.
To stop the theory and be really comfortable when I recommend it to my clients, I decided to do a little test…
The test : what is the impact of chunking on the detection of the entities and of the close semantic ?
To not stay at the level of intuition, I decided to pass the test of fire : the API the Google Cloud Natural Language.
Why ? Well… because this is Google, already. And because it detects the entities, an element of SEO/GEO is often overlooked, when used strategically and intelligently, it is very telling.
Even if this is not exactly the algorithm of ranking, this API is a public mirror of how Google understands the content. It is also a part of the bricks that feed into the Knowledge Graph, so it is still very informative to test the impact of chunking on the understanding semantics.
Purpose of the test : chunking vs non-chunking
Grosso modo, I wanted to measure how the cutting of the content (chunking) influence three key aspects :
- Score saliency (Salience) : the weight of an entity within the overall context of the document (0 to 1)
- Detection of long-tail entities : is technical concepts specific are identified in a content-long and dense
- Score semantics of passages : how the chunking impact on the relationship between the passages, and queries
Assumptions
H0 – long Text (non-chunké) :
The “Global Context” is strong, Google includes the general theme.
But an entity mentioned in the middle of a pad of 2000 words can have a salience is close to zero (0.01), drowned in the noise.
H1 – Text chunké :
By isolating the same entity in a paragraph of 100 words, its salience mechanics should explode.
But… do we lose the categorization of the overall document and the relationships between entities (triples subject-predicate-object) ?
Central Question of the test
The chunking enables it to improve the accurate detection of secondary entities without sacrificing the overall understanding of the document ?
If we cut out a section in slices to satisfy a window of context or a vector index, a risk we break the Thread Semantics (Semantic Thread) ?
KPI of the test on the impact of chunking :
The Score of Salience (Salience Score) is the KPI of this test. The Salience indicates the importance of an entity within the overall context of the document.
- Score close to
1.0: This is the main subject of the text. - Score closer to
0.0: This is a reference to anecdotal.
If your main keyword has a salience is low, you are off-topic in the eyes of Google.
The Test Protocol on the impact of chunking
For content, I opted for the article ‘ Artificial Intelligence ‘ Wikipedia via API to get the wikitext pure (without noise or HTML).
Why ? It is a long, dense, interconnected, and this is the basis of the Knowledge Graph of Google.
So I’m going to use the same article twice. Once without cutting and then a second time with decoupage (chunking).
For the cutting, I used LangChain ‘ RecursiveCharacterTextSplitter'
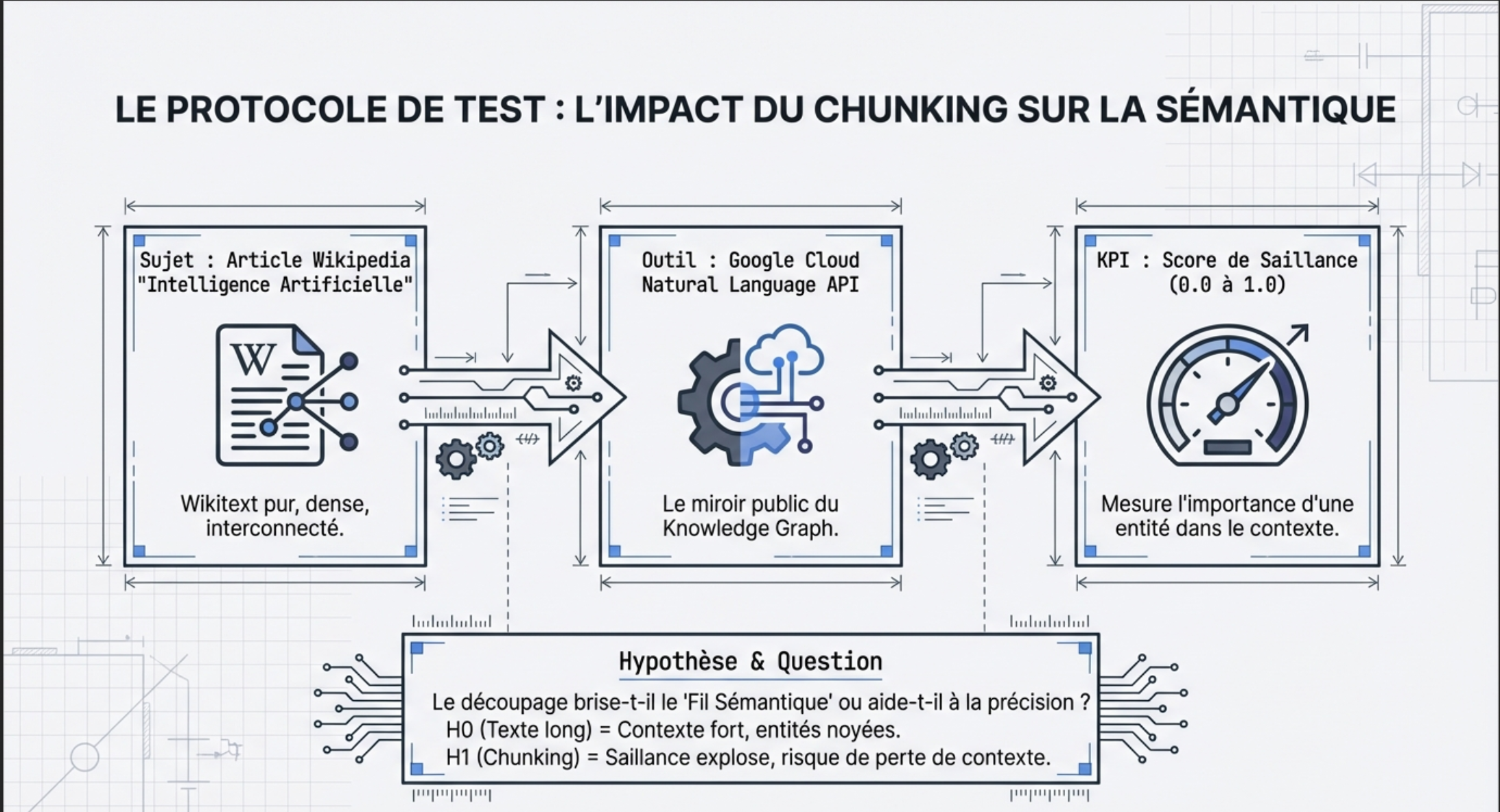
I also play with the settings in the decoupage(to mimic a chunking well made and a chunking amateur)
API Google Cloud Natural Language is involved in the latter for the detection of entities.
PHASE 1 : Analyse du texte complet (Baseline)
- 262 entités détectées dans le texte complet.
- Top entité : intelligence artificielle (Salience: 0.0801)
PHASE 2 : Découpage en chunks (200 chars)
- Texte fragmenté en 82 morceaux.The results ? Chunking, yes or no !
| name | salience_full | avg_salience_chunk | delta_salience |
| computer systems | 0,0362 | 0,064251 | 0,028051 |
| all | 0,0217 | 0,084512 | 0,062812 |
| probabilities | 0,0088 | 0,075053 | 0,066253 |
| computer | 0,0072 | 0,090179 | 0,082979 |
| concepts | 0,0065 | 0,146644 | 0,140144 |
| cognitive science | 0,0065 | 0,114593 | 0,108093 |
| domain | 0,0057 | 0,08105 | 0,07535 |
| linear algebra | 0,0056 | 0,097257 | 0,091657 |
| statistics | 0,0056 | 0,097257 | 0,091657 |
| foundations | 0,0056 | 0,059433 | 0,053833 |
Interpretation of results : the impact of chunking
The explosion of the ‘ Linking Words ‘
- Full Text : Salience of
0.0065(is That a word accessory, background noise). - Chunks : Salience average of
0.1466. - Analysis : Its importance has been multiplied by a factor of 22 !
‘When you reduce the window of context to 200 characters in length (the equivalent of a big tweet), Google loses the sense of proportion. The word ‘Concepts’, which is a generic term in the article overall, suddenly becomes the Main Subject of the passage.
The result SEO/GEO : If Google indexes this fragment to an AI Overview, it might classify this passage to query information very vague (intent mismatch) instead of the file for ‘Artificial Intelligence’. ‘
The phenomenon of ‘ Topic Drift ‘ (Drift Theme)
Take a look at ‘ Probabilities ‘ and ‘ Statistics ‘.
- They earn about +0.06 to +0.09 of salience.
‘In the full article, the statistics are just a tool of the AI. But once the text has been cut, the relationship of subordination is broken. In the chunk isolated, Google no longer sees ‘The AI uses the statistics’ he sees ‘This is a text on statistics’.
Consequently, SEO / GEO : instead of having a page strong on a topic, you end up with 82 pieces low on math topics disparate. This is the cannibalization semantic fragmentation. ‘
The loss of the ‘ Queen Mother, ‘ (The main keyword)
The keyword ‘ artificial Intelligence ‘ (Top entity of the full text with 0.0801) is not in your Top 10 earnings.
It has been crushed by the noise.
While words side as a ‘whole’ or ‘field’ to see their score explode, the real subject of the text is stagnating.
Conclusion ?
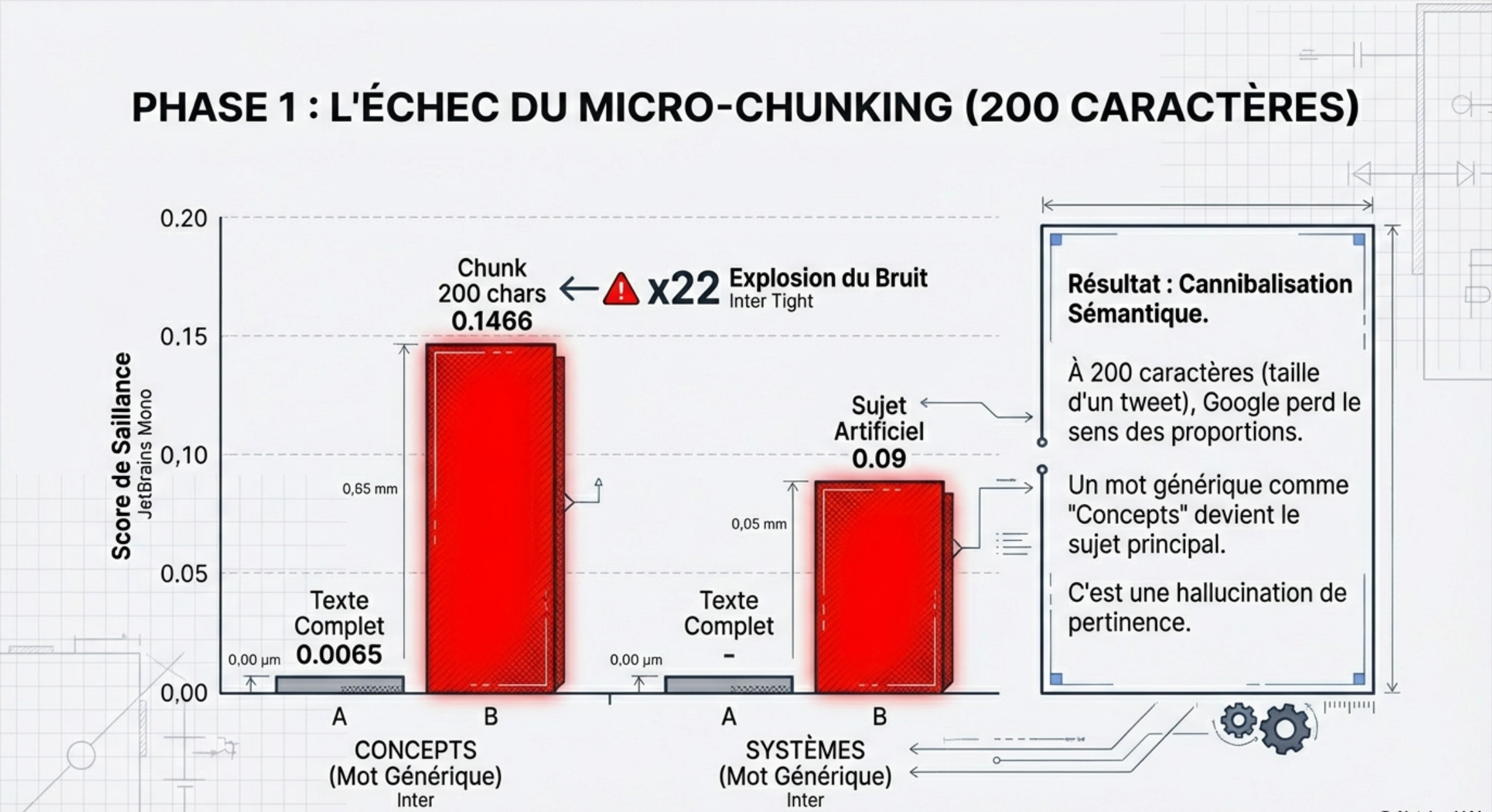
The chunking aggressive (200 characters) creates a sound semantics , which stifles the main signal. For Google, the song was no more talk about AI, he speaks of ‘systems’, of ‘concepts’ and ‘domains’. ‘
200 characters, we are under the threshold of consistency semantics (Semantic Coherence Threshold). If you optimize for the ‘Passages’ with paragraphs of 200 characters, you can’t cut out too late without injecting artificially on the context (ex: repeat the main keyword in each fragment). ‘In that case, repeat the word primary when it is not relevant, is not the best strategy.
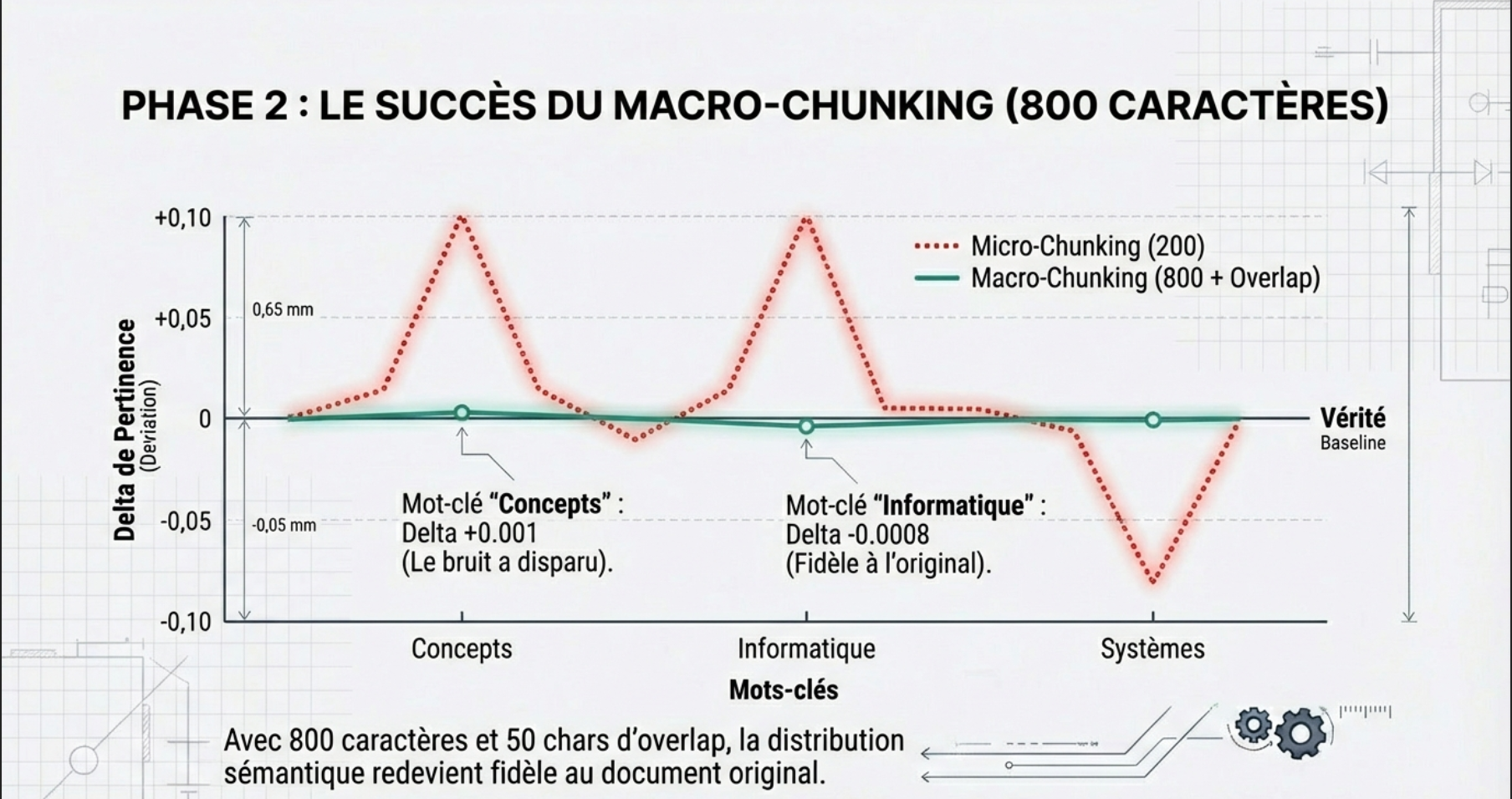
PHASE 2 of the test
With 200 characters, there was an ‘Explosion of Noise’ (generic words were main topics).
So I rerun the test by quadrupling the size of the fragments (800 characters) and adding a drizzle of safety (up to 50 characters of overlap to not cut the sentences). The results are without appeal.
The collapse of the noise is generic (The calm)
If we look at the word : ‘the Concepts of’ one more time :
- Test 200 tanks Delta +0.14 (a Huge hallucination of relevance).
- Test 800 tanks : Delta +0.001 (Near zero).
Passing to 800 characters (approximately one full paragraph), Google has enough words around to understand that the ‘concepts’ is not the subject, but just a word in the sentence,. The context has diluted the noise.
The lesson SEO / GEO : A fragment must contain enough words to that the AI can make the difference between the Topic and the Vocabulary.
The appearance of the Deltas Negative : A sign of health
If one looks at the word : ‘ It ‘
- Test 200 chars : +0.08 (Suroptimisé).
- Test 800 tanks : -0.0008 (Slightly under-valued).
The distribution of the importance in the chunk begins to resemble that of the complete text.
With 800 characters (approximately 120 words), we offer Google the equivalent of a paragraph structured. The analysis shows that the scores of salience were closer to those of the full document. Not bad, eh !
The impact of the Overlap (Overlap)
50 characters overlap have helped to smooth the transitions. We no longer feature cut in two that generate false positives. ‘
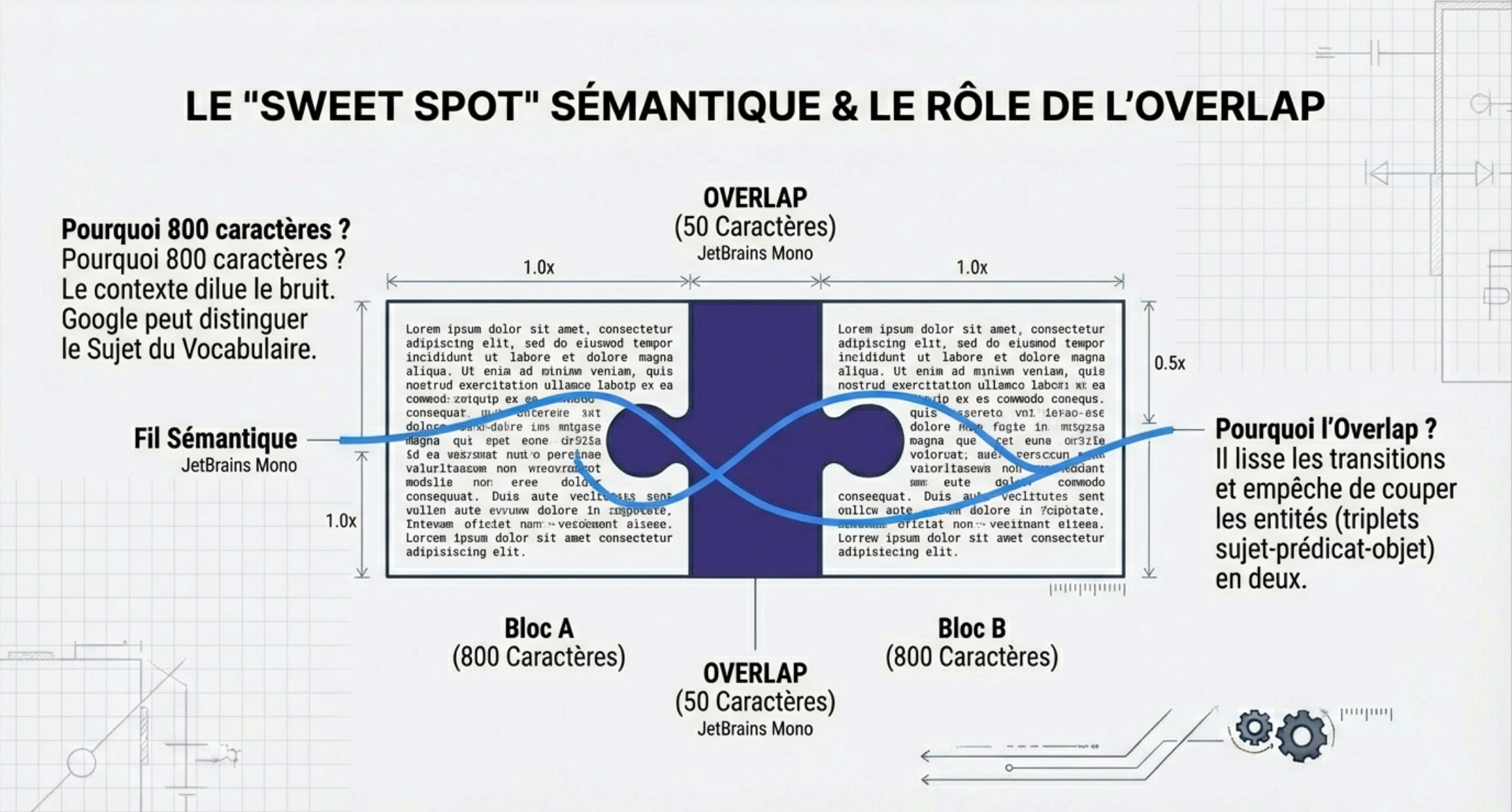
The ‘ Sweet Spot ‘
If we look at the computer system, It remains higher (+0.06). This indicates that this term is probably the central topic of a paragraph or two specific. 800 characters, Google correctly identifies this sub-topic without hallucinate on empty words.
My opinion SEO / GEO on the chunking
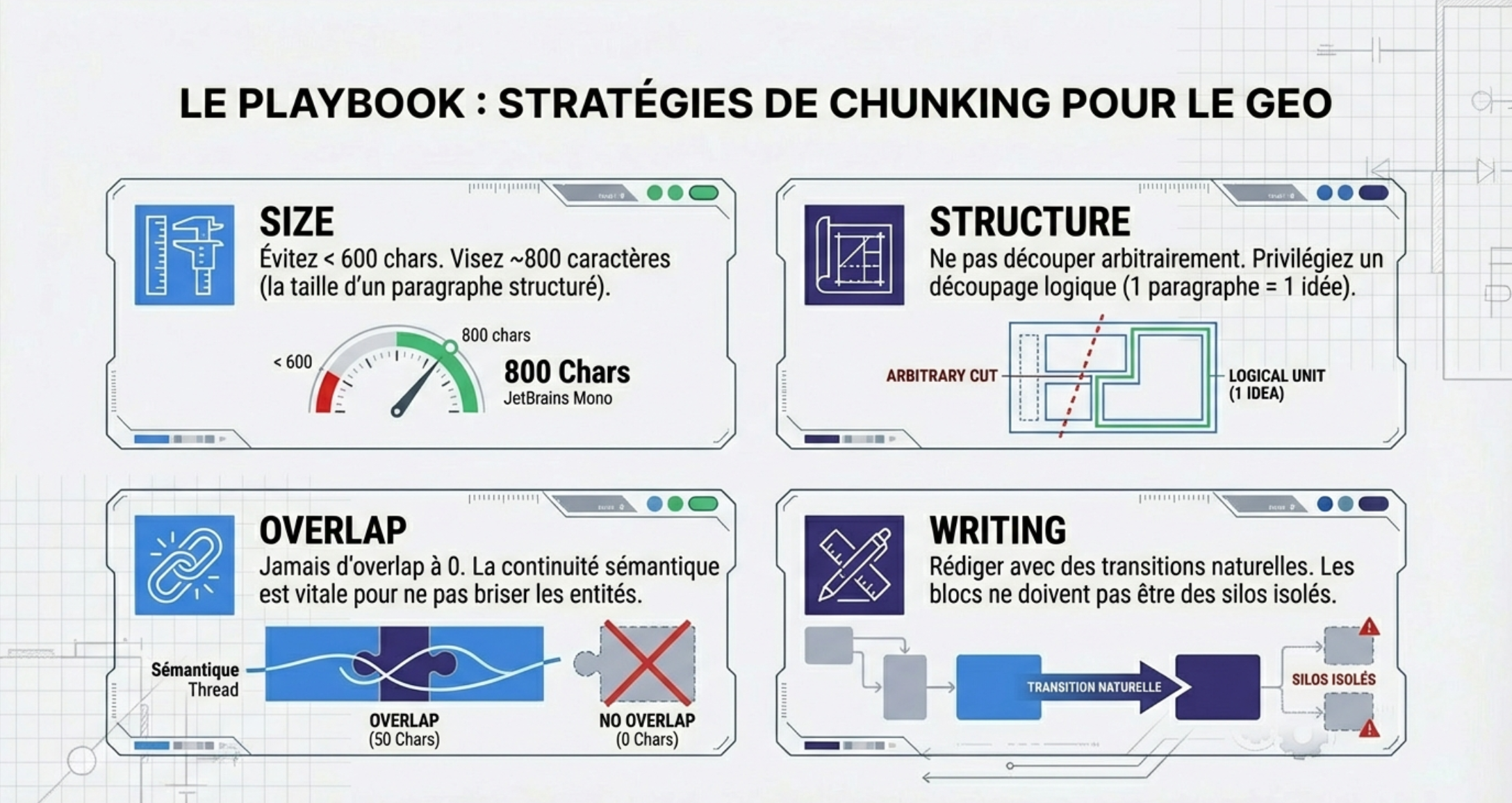
- Avoid the chunks that are too short : below 600 to 800 characters, the cutting becomes too granular and traced the noise semantics instead of real signals.
- Choose a division close to the paragraph : blocks broader allow to better identify the sub-topics consistent and usable in GEO.
- Do not neglect the chunk overlap : with an overlap to 0, the continuity semantics is broken and the performance drops.
- Next to writing, that involves transitions natural between paragraphs and the continuity of the terms and ideas : the blocks should never be run as isolated silos. It is therefore necessary to find the right balance between independence paragraphs, and continuity of ideas.
Leave a Reply